
Istnieje wiele linii podziału baz danych ze względu na model. Jedną może być stopień i sposób ustrukturyzowania danych. Inną wykorzystanie języka SQL. Ja wyróżniam dwa kluczowe modele: relacyjny obsługiwany językiem SQL oraz całą resztę. W reszcie jeden lśni jak diament. Skomentuj czy domyślasz się jaki to model.
Czy tylko ja uważam model relacyjny za kluczowy?
Być może nie wyraziłem tego dostatecznie dobitnie w poprzednich materiałach. Powtórzę, więc. Dane to najcenniejszy zasób każdej organizacji. Jak są cenne niech świadczą fakty, że wiodący dostawcy chmury pozwalają nam trzymać nasze dane w swoich chmurach za darmo. Wyniesienie korporacyjnych danych do chmury jest tanie. Zabranie ich z chmury jest drogie.
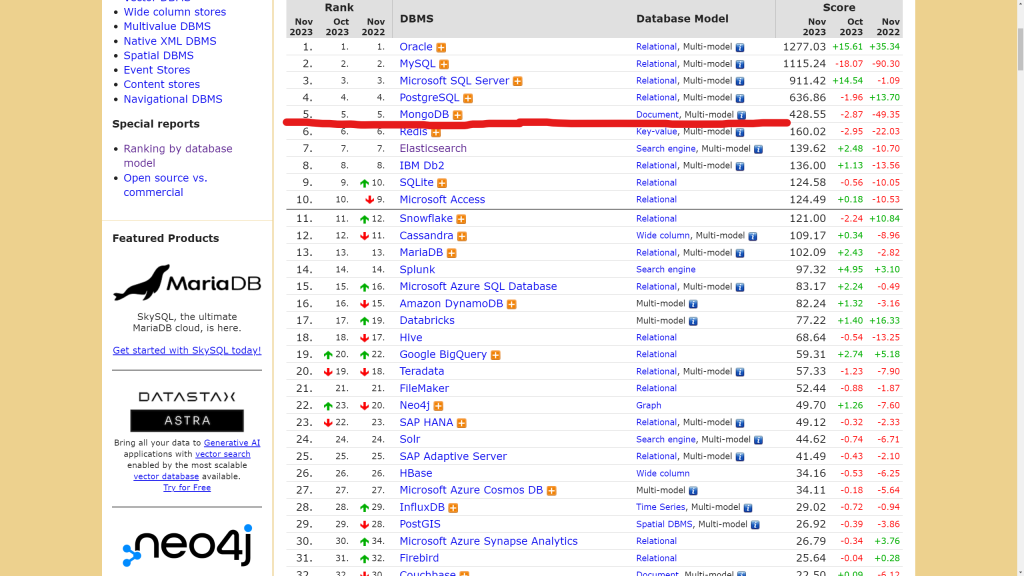
Statystyki prowadzone przez portal DB-Engines wskazują, że większość ludzi pracujących z danymi rozumie jak są cenne. Pierwsze cztery miejsca zajmowane są przez motory baz danych o relacyjnych korzeniach. Stosunek punktacji motorów z pierwszej dziesiątki to prawie 6:1 na korzyść relacyjnych. Czyli motory relacyjne są ponad 5,9 razy bardziej popularne niż pozostałe.
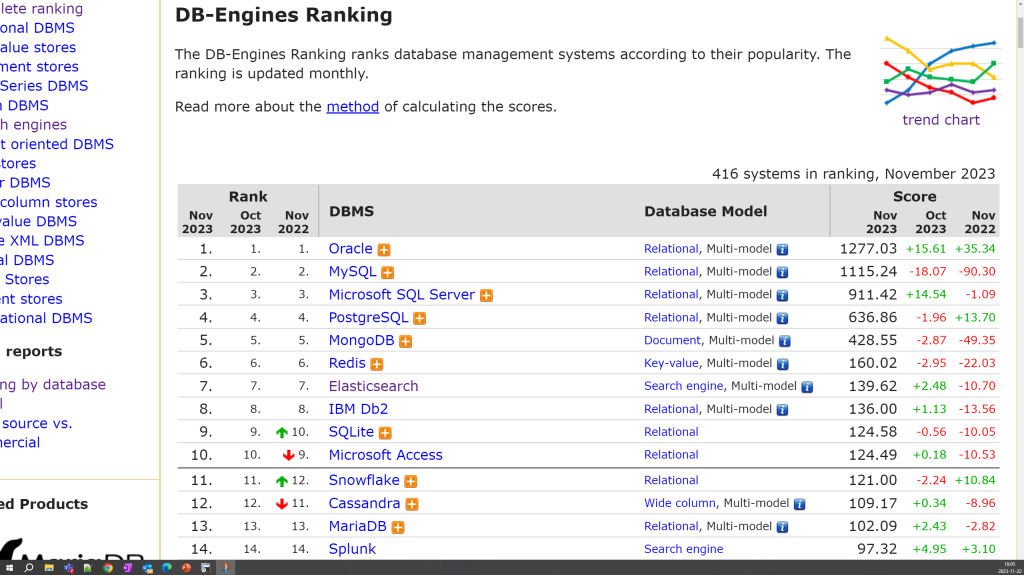
Świadczą o tym także dochody producentów motorów. W raporcie Gartnera za rok 2021 pierwsze 5 miejsc zajmują firmy produkujące motory obsługujące różne modele. Nie ma danych pokazujących jaki odsetek dochodu przypada na model relacyjny. Niemniej wszyscy producenci specjalizujący się w modelach nierelacyjnych to jedynie 20% rynku baz danych.
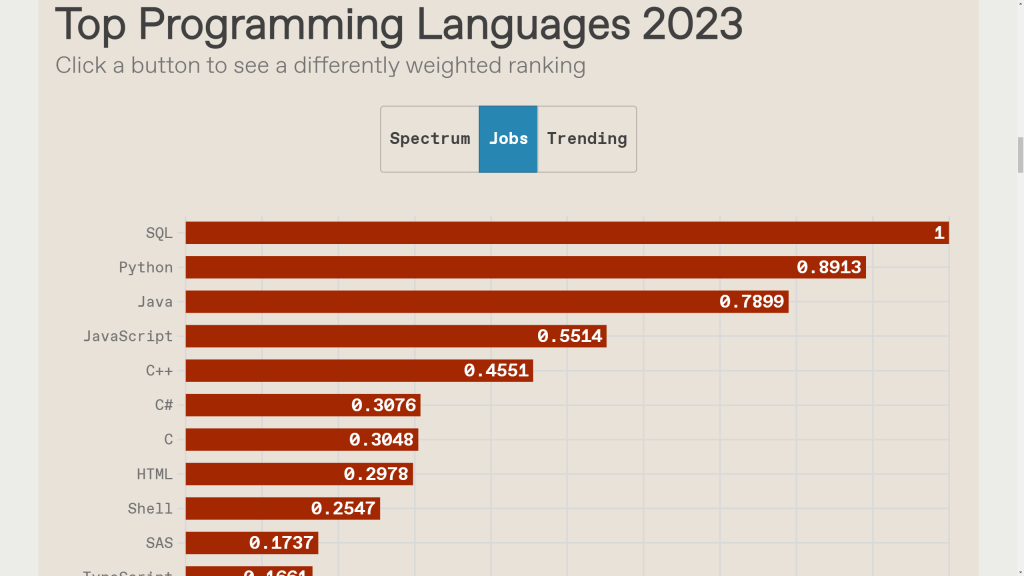
Dane przechowywane w dowolnej bazie danych byłyby bezwartościowe bez mechanizmu dostępu do nich. Od 50 lat najlepszym API do danych jest język SQL. Dobrze rozumieją to zarówno użytkownicy danych jak i producenci motorów. Według IEEE w 2023 język SQL jest najbardziej pożądaną przez pracodawców umiejętnością. Niemniej trzeba dodać, że niewystarczającą.
Język SQL jest ściśle związany z modelem relacyjnym. Kiedyś producenci motorów nierelacyjnych reklamowali się określeniem 'nosql’. Później spuścili z tonu na 'not only sql’, a obecnie mienią się po prostu nierelacyjnymi. Część z nich zaimplementowała język SQL w swoich produktach. O języku SQL będzie kolejny materiał.
Technikalia modelu relacyjnego
Z technicznej perspektywy model relacyjny najlepiej wspiera jakość danych. Zapewnia silne typowanie. To znaczy, że motor bazy danych nie pozwoli Ci na wstawienie napisu w miejsce liczby. Dodatkowo, jako twórca struktury bazy danych, możesz zdefiniować ograniczenia zakresu danych. Czyli definiując mechanizmy zwane więzami integralności możesz wymusić zakres przyjmowanych danych. Na przykład nie pozwolić na wstawienie liczby ujemnej gdy zależy Ci tylko na dodatnich.
Trzeba pamiętać, że baza danych to tylko zbiór bajtów w pliku. To jak te bajty mają być interpretowane przez motor – jako liczby, napisy czy daty – definiuje twórca bazy danych tworząc jej struktury. Dzięki zdefiniowanym strukturom motor bazy danych wie ile bajtów składa się na liczbę czy napis, ale także nie pozwoli na wstawienie większej ilości bajtów niż twórca bazy danych przewidział. Informacje te nazywane są metadanymi. Czyli danymi o danych. Zapisane są w tak zwanym słowniku bazy danych. Osobno od samych danych.
Skąd nazwa 'model relacyjny’?
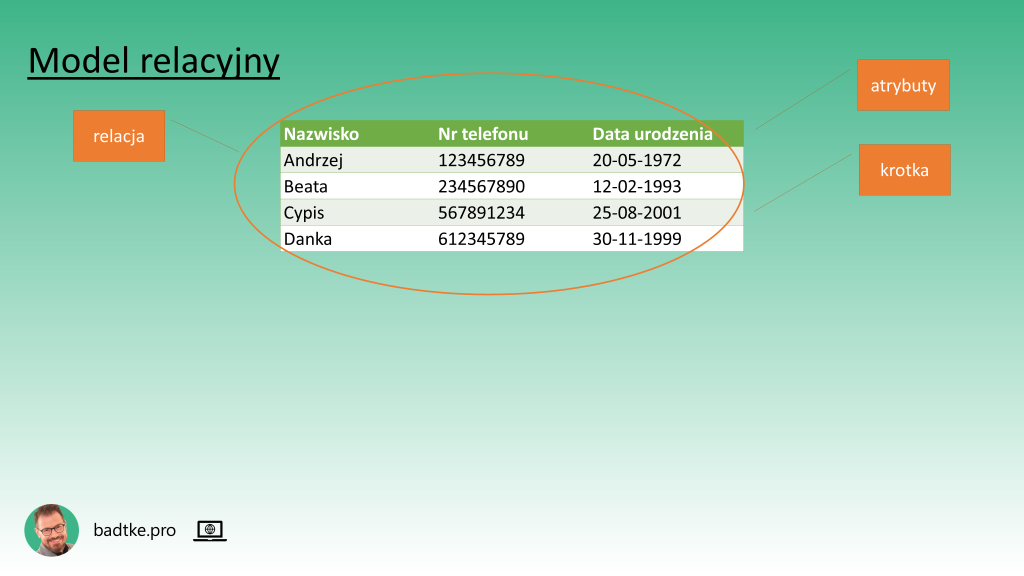
Nazwa modelu podkreśla dbałość o powiązania – relacje – pomiędzy danymi. Związki pomiędzy danymi przebiegają na dwóch poziomach. Pierwszy to powiązanie wspólnymi atrybutami. Na przykłąd chcesz gromadzić dane o swoich znajomych. O każdym znajomym planujesz przechowywać atrybuty jak nazwisko, numer telefonu i datę urodzenia. Czyli dla każdego znajomego będziesz przechowywać podobny zbiór wartości atrybutów. Każdy z tych zbiorów wartości, czyli zestaw danych nazwisko, numer telefonu i data urodzenia, w modelu relacyjnym nazywany jest krotką. A krotki o takim samym zestawie atrybutów grupowane są w strukturę nazywaną relacją. Natomiast znajomy o którym przechowujesz dane to encja. Czyli taki bazodanowy byt o którym zbierasz fakty.
Drugim poziomem powiązania danych w modelu relacyjnym jest wiązanie danych ze względu na wartość atrybutów. Czyli do swojej bazy danych o znajomych decydujesz się dołożyć dane o ich adresach. Potrzebujesz ulicę z numerem domu i mieszkania oraz nazwę miasta z kodem pocztowym. W efekcie dysponujesz dwoma relacjami. Jedna grupuje znajomych druga ich adresy. Potrzebne jest jeszcze powiązanie który adres należy do którego znajomego. Takie powiązanie tworzysz powielając fragment danych jednoznacznie identyfikujący krotkę. Na przykład powielasz nazwisko znajomego w relacji adresów.
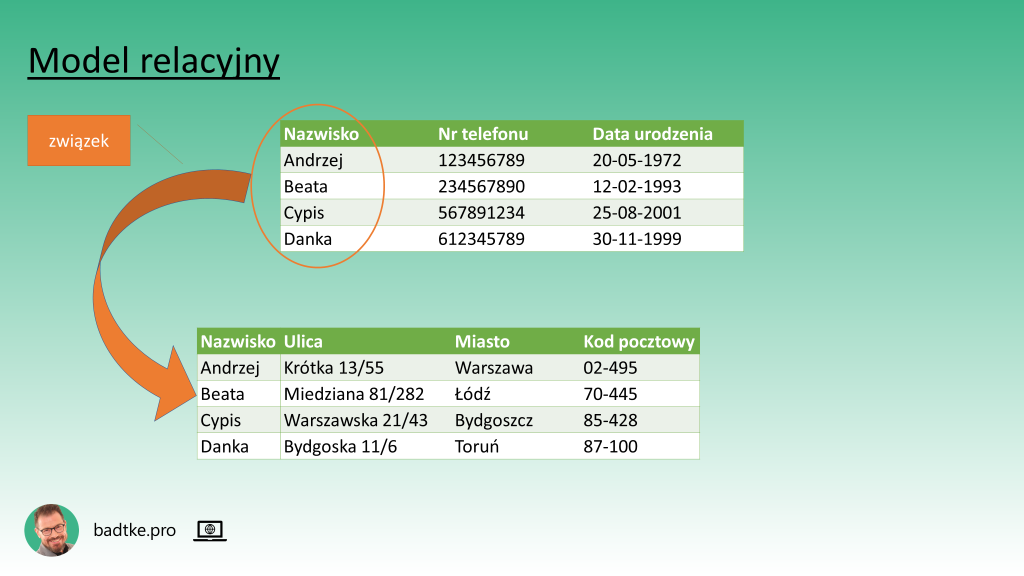
Powiązanie danych ze względu na ich wartości daje bardzo wiele możliwości. Jest to temat tak obszerny, że zasługuje na osobny materiał. Daj znać w komentarzu czy byłby dla Ciebie wartościowy.
Zalety modelu relacyjnego
Znajomość i umiejętne wykorzystanie mechanizmów wspierających jakość danych gwarantują, że dane przechowywane w bazie danych są zgodne z faktami interesującymi Twoją firmę. Mogą służyć jako wiarygodne źródło prawdziwych informacji. W połączeniu z technikami jak normalizacja i ACID dają w efekcie stosunkowo niewielką i szybką bazę danych. Bardzo dobrze sprawdzającą się zarówno w zastosowaniach OLTP jak i OLAP.
Normalizacja to proces wspierający jakość danych. Jego celem jest eliminacja duplikatów i wsparcie integralności danych. Dane rozkładane są na jak najmniejsze, przydatne dla przedsiębiorstwa, fragmenty i umieszczane we wspierających ich jakość sztywnych strukturach bazy danych. Na przykład w trakcie normalizacji podejmujesz decyzję czy atrybut numer telefonu rozbijasz na dwa atrybuty: kierunkowy kraju i numer właściwy. Nie ma miejsca na zagnieżdżanie danych. Na przykład na przechowywanie krotki czy relacji w atrybucie. Także przechowywanie tablic w atrybutach jest niezalecane i powinno być eliminowane w procesie normalizacji.
ACID to zestaw cech, którymi musi wykazywać się operacja manipulująca danymi w bazie danych. Celem jest zabezpieczenie jakości danych pomimo przeciwności. Czyli zabezpieczenie spójności bazy danych. Na przykład pomimo błędów działania aplikacji czy padu instancji bazy danych. Właściwości ACID są integralną częścią motorów relacyjnych.
Inną zaletą jest dojrzałość technologii relacyjnej. Ma za sobą około 50 lat rozwoju co owocuje ogormem dostępnej wiedzy, narzędzi i doświadczenia. Na rynku istnieje wielu doświadczonych specjalistów potrafiących projektować relacyjne bazy danych oraz obsługiwać relacyjne motory. Same wiodące motory relacyjne mają za sobą dziesiątki lat rozwoju. Przez ten czas obrosły bogatą funkcjonalnością oraz wysokim poziomem bezpieczeństwa danych.
Wady modelu relacyjnego
Stosunkowo sztywna struktura relacyjnej bazy danych jest zaletą jeśli chodzi o jakość danych natomiast wadą w zastosowaniach wymagających jej szybkiej zmiany. Bazy danych przechowują coraz więcej danych. Zmiana struktury modelu relacyjnego często wymaga fizycznego przepisania dużej ilości danych w inne miejsce dysku. Każda taka zmiana jest zasobochłonna. Nie każdy motor udostępnia funkcjonalność pozwalającą dokonywać takiej zmiany bez ograniczania użytkownikom dostępu do danych.
Skalowanie horyzontalne relacyjnych baz danych nastręcza problemów. W efekcie można dotrzeć do momentu w którym Twojej instalacji zabraknie mocy obliczeniowej do obsłużenia ruchu w bazie danych. Według mnie w dużej części może to być spowodowane nieoptymalną jej strukturą oraz nieoptymalnymi komendami SQL. Niemniej istnieją produkty wspierające, w mniejszym lub większym stopniu, przetwarzanie rozproszone w bazach relacyjnych. O skalowaniu poziomym mówiłem w materiale o architekturach baz danych. Szczegółowe omówienie przeszkód wykracza poza zakres tego materiału. Jeśli taka wiedza jest wartościowa dla Ciebie daj znać w komentarzu.
50 lat historii powoduje, że model relacyjny nie jest medialny. Mimo ciągłej ewolucji nie znajduje się na szpicy rozwoju technologicznego. Raczej jest dostosowywany do zmieniających się wymagań. W efekcie, przez nowe pokolenia specjalistów IT, nie jest postrzegany jako technologia warta zgłębienia. Oczywiście ogromna popularność tego modelu oraz stosunkowo wysokie zarobki programistów baz danych, administratorów baz danych oraz analityków danych powodują zainteresowanie młodzieży. Niemniej w dużej mierze jest to zainteresowanie powierzchowne. Wystarczające aby dopisać do CV, ale niewystarczające do zaprojektowania optymalnej struktury bazy danych oraz sposobu przetwarzania danych. Wyrazem tego jest dostępność wiedzy w szkolnictwie wyższym. Gdzie ilość godzin dotycząca baz danych jest znikoma w porównaniu do szerokości tematu. Owocem tego są programiści niewolniczo przywiązani do narzędzi ORM i poznanego języka programowania. Przedkładający przetwarzanie danych w aplikacji zamiast w stworzonej do tego celu bazie danych.
Geneza modeli nierelacyjnych
Modele nierelacyjne powstały w kontrze do głównych cech modelu relacyjnego. Czyli sztywnej pozbawionej nadmiarowości relacyjnej struktury danych, języka SQL oraz skupienia na właściwościach ACID. Lśniącym diamentem, wśród modeli nierelacyjnych, jest dokumentowy. Odpowiada na potrzeby firm dotyczące nie tylko przechowywania dokumentów, ale także ich wydajnego przetwarzania. Wiodący producenci motorów relacyjnych umożliwiali przechowywanie dokumentów w bazach danych swojej produkcji. Niemniej nie dostarczali narzędzi do ich wydajnego przetwarzania. Sposób składowania danych, język manipulujący nimi oraz algorytmy przetwarzania dostosowane do modelu relacyjnego nie były optymalne dla danych dokumentowych.
Trzeba pamiętać, że wszystkie dane ustrukturyzowane są w bazie danych i jej plikach w taki sposób aby jak najbardziej wydajnie je przetwarzać. Im większa moc obliczeniowa komputerów i im tańsze nośniki danych tym luźniej ustrukturyzowane dane opłaca się komputerowo przetwarzać.
Technikalia modelu dokumentowego
Najbardziej popularną bazą dokumentową jest MongoDB. Jest to jedyna dokumentowa w pierwszej trzydziestce rankingu DB-Engines. Skupię się, więc na niej.
Dokumenty składowane są w swojej oryginalnej wysoce nadmiarowej formie. Dużą część, liczonej w bajtach, objętości przypada na metadane. Czyli dane opisujące dane. Oraz na opis struktury dokumentu. Metadane zapisane są razem z danymi. W tym samym pliku. Są integralną częścią dokumentu i w każdym są powielane. Aby obniżyć konsumpcję nośnika stosowana jest kompresja danych.
Dokument zazwyczaj jest w fomacie JSON. Czyli jest to tekst składający się z par nazwa atrybutu i jego wartość. Pomiędzy nazwą, a wartością jest dwukropek. Wszystko otoczone różnego rodzaju nawiasami. Wartość atrybutu może być nie tylko typu prostego jak napis czy liczba, ale także inny dokument czy tablica składająca się z par atrybut wartość. Czyli możliwe jest zagnieżdżanie. Jest to bliższe formatowi przechowywania danych w aplikacji.

Poszczególne dokumenty grupowane są logicznie w kolekcje, które nie wymuszają określonej struktury dokumentu. Motor bazy danych przyjmie każdy dokument niezależnie od jego struktury. W jednym dokumencie wartością atrybutu może być napis, a w innym dla tego samego atrybutu może być przypisana liczba lub tablica.
Wszystkie kolekcje i dokumenty są zupełnie niezależnymi bytami. Wartość jednego atrybutu w żaden sposób nie może wpłynąć na wartość innego w jakimkolwiek dokumencie. Podobnie dokumenty czy kolekcje. Istnienie jednego w żaden sposób nie zależy od innego.
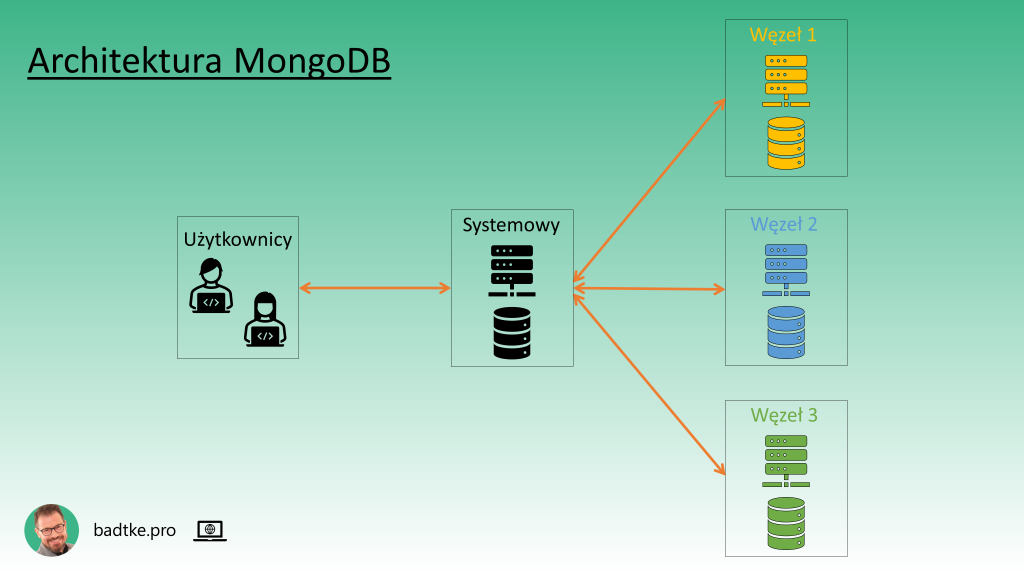
Warto mieć na uwadze, że MongoDB jest motorem zaprojektowanym do obsługi rozproszonych baz danych. Podejście twórców MongoDB hołdowało twierdzeniu CAP. CAP jest angielskim akronimem oznaczającym:
- Consistency
- Availability
- Partition tolerance
Rozproszone systemy są w stanie gwarantować jedynie dwa z trzech postulatów CAP. Jeśli brzmi zbyt nerdowo to nic dziwnego bo swoje korzenie ma w informatyce teoretycznej. Za ojca teorii uważany jest profesor Eric Brewer. Daj znać w komentarzu czy aspirujesz do miana nerda i chcesz więcej na ten temat. Póki co zapamiętaj jedynie, że MongoDB musiało pójść na kompromisy aby osiągnąć rozproszenie bazy danych, elastyczność struktury i wydajność w przetwarzaniu dokumentów. Innymi słowy poświęcono dostępność na rzecz spójności i odporności na rozczłonkowanie. Nic nie jest za darmo.
Zalety MongoDB
Według mnie największą zaletą MongoDB jest elastyczność struktury. Dokumenty podzielone są jedynie na bazy danych i kolekcje. Nie ma żadnych wymagań jeśli chodzi o format dokumentu ani żadnych powiązań. Jest to bardzo wygodne dla programistów. Mogą w bardzo prosty sposób przechowywać dokumenty w formacie JSON. Kolejnym ukłonem w strone deweloperów jest zaimplementowany w motorze JavaScript. Nie bez przyczyny MongoDB reklamuje się jako 'first developer data platform’.

Inną zaletą jest rozproszenie bazy danych. Jak wspominałem w materiale o architekturach rozproszone bazy danych łatwo skalują się poziomo. Czyli w stosunkowo łatwy sposób można dołożyć mocy obliczeniowej oraz wydajności dysków. Warto pamiętać, że obsługa rozproszonej bazy danych, podobnie jak replikacja danych, jest integralną częścią MongoDB.
W internetach można spotkać się z peanami na cześć wydajności motoru. Wydajność ta sprawdza się w konkretnych zastosowaniach. Sądzę, że przyczyną dobrej wydajności są skompresowane i silnie poindeksowane dane. Dzięki rozproszeniu MongoDB ma do dyspozycji moc obliczeniową i pamięć RAM wszystkich węzłów klastra.
Wady MongoDB
Moim zdaniem największą wadą MongoDB jest brak ścisłej dbałości o jakość danych. Przejawia się w braku kontroli struktury przyjmowanych dokumentów oraz ograniczonej transakcyjności. Kierunek rozwoju obrany przez producentów motoru wskazuje, że nie tylko ja postrzegam te kwestie jako wady. Trwają prace nad transakcjami obejmującymi zmiany w wielu dokumentach oraz możliwością wymuszania struktury wstawianego dokumentu.
Problematyczna jest obsługa współbieżności. Czyli żądań manipulacji danymi przez wielu użytkowników w tym samym czasie. Wynika to z krótkowzrocznej implementacji mechaniznów kontroli współbieżności i blokowania danych.
Rozproszenie skonstruowane jest w oparciu o jeden węzeł systemowy przyjmujący wszystkie zapisy i żądania odczytu. Podobnie jak opisane w materiale o architekturach baz danych.
W przypadku padu węzła systemowego klaster staje się niedostępny. Obowiązki systemowego podejmuje inny mający najświeższe dane węzeł. Następnie informuje wszystkie pozostałe o swojej nowej roli.
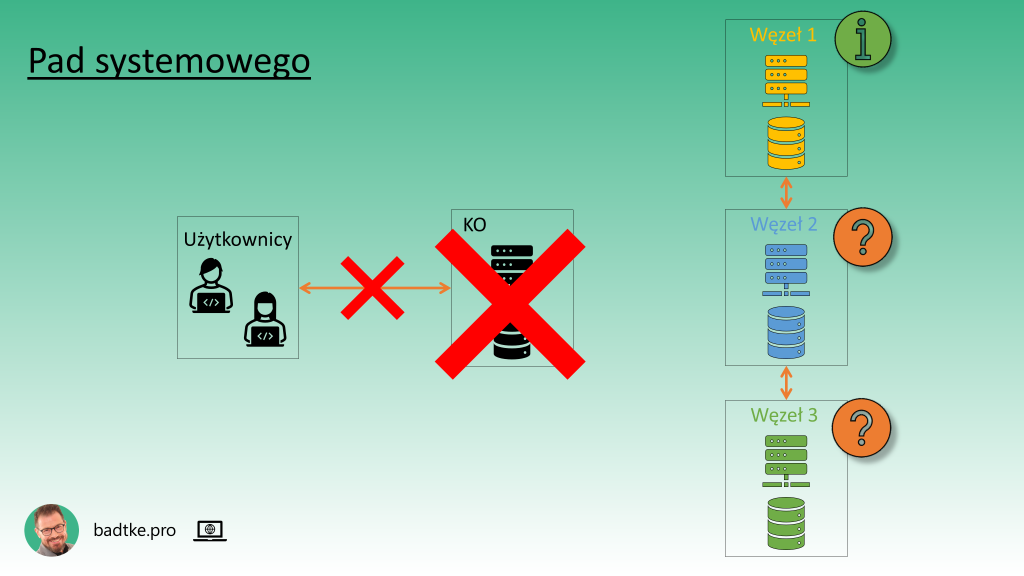
Gdy wszystkie węzły wejdą w posiadanie tej informacji klaster znów jest dostępny. Może to owocować utratą danych.
Niekonwencjonalne podejście do przetwarzania danych zaimplementowane w MongoDB wymaga odpowiednio przeszkolonych specjalistów. Odpowiedni podział danych na bazy danych i kolekcje oraz indeksowanie odpowiadające potrzebom aplikacji wymaga doświadczenia. Podobnie z językiem pozwalającym na manipulowanie danymi. Trzeba zaznaczyć, że zapytania wiążace dane z różnych kolekcji nie są trywialne.
Stosunkowa młodość projektu owocuje błędami wieku dziecięcego. Błedy związane są z domyślną konfiguracją bezpieczeństwa, nastręczającym problemów skalowaniem oraz ograniczną funkcjonalnością samego motoru jak i języka zapytań. Niemniej trzeba zaznaczyć, że producent MongoDB stara się sukcesywnie eliminować problemy.
Według mnie popularność motoru MongoDB nieco przerosła jego twórców. Z uwagi na niską barierę wejścia – deweloper nie musi nic wiedzieć o bazach danych – MongoDB bywa używane do zastosowań do których nie zostało zaprojektowane.
Model klucz-wartość
Po modelu dokumentowym jest długo, długo nic i dopiero model klucz-wartość. Później znów długo, długo nic i model grafowy.
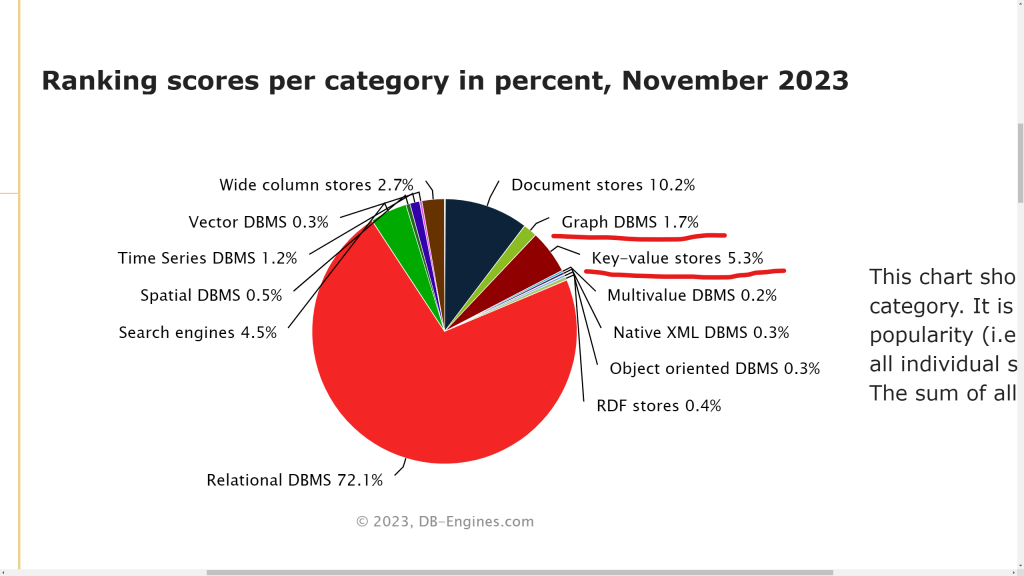
Reszta jest tak niszowa, że nie godna uwagi. Jeśli uważasz inaczej albo uraziłem Twoje gorące uczucia do, na przykład, modelu obiektowego daj temu wyraz w komentarzu.
Model klucz-wartość z angielska key-value. Służy do przechowywania par: unikalny klucz oraz skojarzone z nim dane. Dane wyszukiwane są według unikalnego klucza – identyfikatora. Klucz może być prosty lub złożony. Dane mogą być prostych typów jak łańcuch znaków czy liczba lub skomplikowanych jak obiekt. Przykładem takiej bazy danych może być rejestr w Windows. Kluczem wyszukiwania jest ścieżka do danych lub unikalny identyfikator. Strukturę możesz wyobrazić sobie jako przypominającą słownik gdzie każdemu unikalnemu hasłu odpowiada jakaś definicja.
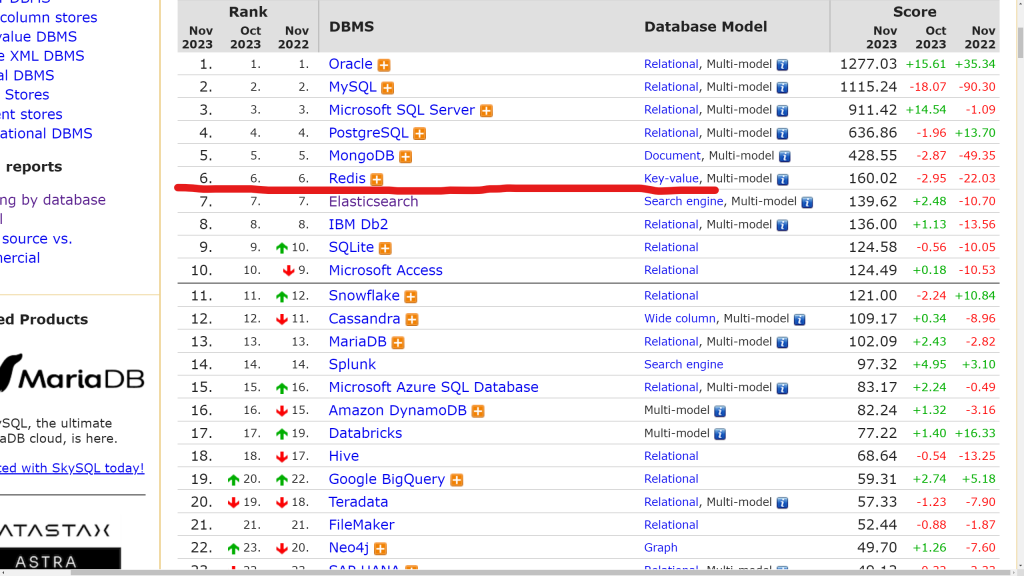
W bazach danych optymalizowanych pod model klucz-wartość nacisk położono na wyszukiwanie danych. Na kluczach zbudowany jest niezwykle wydajny indeks umożliwiający natychmiastowe odnalezienie pożądanego identyfikatora. Mówiąc natychmiastowe mam na myśli w czasie rzeczywistym. Według DB-Engines najbardziej popularnym motorem obsługującym ten model jest redis.
Bazy danych klucz-wartość używane są na przykład do przechowywania danych o sesjach użytkowników w grach massive multiplayer. Lub jako mechanizm pamięci podręcznej dla często używanych danych. Mogą tego używać telekomy do przechowywania stanów konta telefonów pre-paid.
Model grafowy
Ostatnim wartym wspomnienia modelem danych jest grafowy. W dużym skrócie służy do modelowania kto z kim jest w jakim związku. Popularnym przykładem użycia może być drzewko znajomości w mediach społecznościowych czy struktura zakupów w sklepie internetowym.
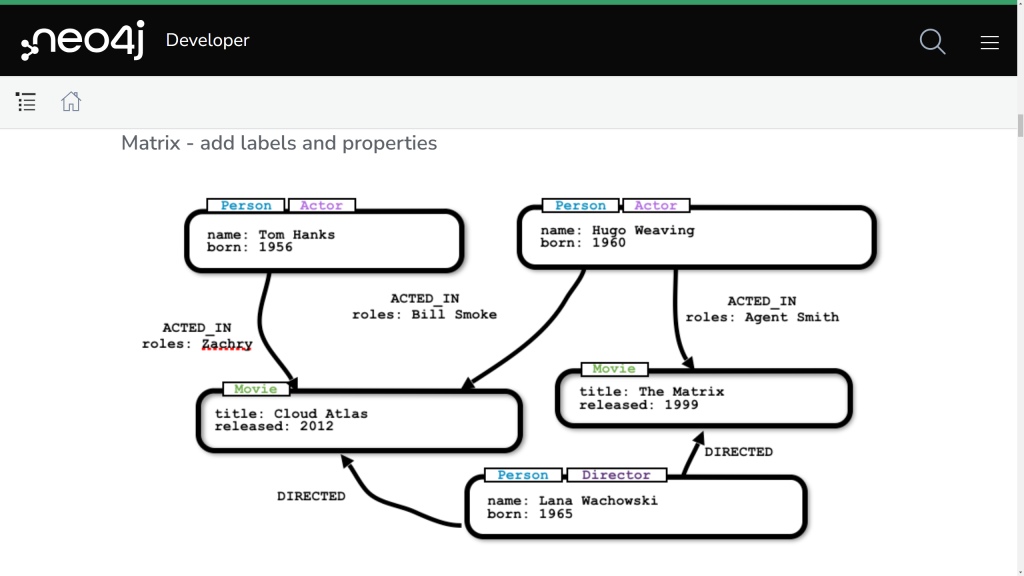
Model grafowy kładzie nacisk na powiązania pomiędzy encjami. Czyli to co w modelu relacyjnym było dokonywane wartościami atrybutów, a w modelu dokumentowym nie istniało tutaj jest podstawą. Dzięki temu model grafowy świetnie nadaje się do odzwierciedlania bardzo skomplikowanych i wielopoziomowych powiązań. Powiązanie pomiędzy danymi jest bezpośrednie. Składowane razem z danymi. Powiązaniom możesz nadawać nazwy, kierunek oraz cechy.
Implementacja modelu grafowego jest ciągle w początkowej fazie. Nie ma natywnego sposobu składowania danych. Używane są mechnizmy składowania motorów relacyjnych, dokumentowych czy klucz-wartość. Nie ma także uniwersalnego języka. Choć są prowadzone prace w kierunku standardu instytucjonalnego GQL – graph query language oraz standardu open-source GraphQL. Czyli standardem jest brak standardu.
Model grafowy jest bardziej naturalny w obsłudze dla obiektowych języków programowania. Jest łatwiejszy w utrzymaniu i bardziej elastyczny niż model relacyjny. Jest także bardziej wydajny gdy przechowuje skomplikowane powiązania ogromnej ilości danych. Nie dziwi więc jego wykorzystanie przez potentatów jak Facebook, Google czy X (kiedyś Twitter).
Z drugiej strony warto pamiętać o niefektywności operacji, które nie zależą głównie od powiązań. Na przykład manipulacja pojedynczymi krotkami czy ich małymi zbiorami. Zapytanie bardziej skomplikowane niż 'wybierz wszystkich gimnazjalnych znajomych Cypisa’ może być wyzwaniem. Nie można także zapominać o nadmiarowości składowania oraz dostępności wiedzy i specjalistów modelu grafowego.
Według DB-Engines najbardziej popularnym motorem optymalizowanym pod model grafowy jest neo4j.
Multimodel
Różne sposoby modelowania danych istniały zanim stały się medialne. Motory zoptymalizowane pod model relacyjny powstały jako pierwsze. Wyparły modele jak hierarchiczny czy sieciowy bo były tańsze i bardziej elastyczne niż mainframe. Na początku XXI wieku powstały i zyskały na popularności motory zoptymalizowane do obsługi innych niż relacyjny modeli danych. Bo przetwarzanie mniej ustrukturyzowanych danych zaczęło być opłacalne. Rynek baz danych urósł ogromnie od lat siedemdzisiątych XX wieku. W 2021 do podziału było $80 miliardów. Zrozumiałe, że rywalizacja jest zaciekła.

Producenci motorów albo dostosują swoje produkty albo zostaną wyparci z rynku. Motory wspierające tylko jeden model danych to margines. Zarówno producenci relacyjnych rozbudowują swoje produkty o modele nierelacyjne jak i producenci motorów nierelacyjnych zaczynają wspierać jakość danych oraz inne modele nierelacyjne.
Nierelacyjne motory multimodel współdzielą kluczowe zalety jak skalowanie poziome, elastyczna struktura danych oraz składowanie zoptymalizowane pod nadmiarowe dane nierelacyjne. Współdzielą także wady jak brak dbałości o jakość danych, hermetyczny język zapytań czy niedojrzałość implementacji. Według mnie największą wadą jest architektura tych motorów niesamowicie utrudniająca adopcję modelu relacyjnego.
Dlaczego model relacyjny jest taki ważny wyjaśniłem wcześniej. Zalety silnych typów i sztywnej struktury dostrzegają nawet piewcy modeli nierelacyjnych. Zgadzam się, że nie wszystkie dane muszą być przechowywane w sztywnych relacyjnych strukturach. Niemniej dane mające wpływ na finanse powinny lub wręcz muszą.
I tutaj, cali na biało, wkraczają producencji do niedawna motorów relacyjnych. Jak Oracle, Microsoft czy PostgreSQL. Zareagowali na potrzeby rynku i dołożyli obsługe modeli nierelacyjnych do swoich flagowych relacyjnych produktów. Dostosował się także standard języka SQL i zaczął wspierać manipulacje danymi nierelacyjnymi. Jest to propozycja godna rozważenia. Wybierając motor multimodel wiodącego dostawcy otrzymujesz jednolitą dbałość o jakość danych i ich bezpieczeństwo niezależnie od modelu. Dostajesz dobrze znany i sprawdzony przez dziesięciolecia język zapytań. Możesz korzystać z bogatej wiedzy, doświadczenia i dostępności licznych specjalistów. Część producentów udostępnia rozwiązania pozwalające na efektywne składowanie danych nieznormalizowanych. Umożliwia ich transparentną deduplikację oraz kompresję.
Podsumowanie
Główną różnicą pomiędzy modelem relacyjnym i dokumentowym jest rozłożenie ciężaru dostosowania. Model relacyjny wymaga aby aplikacja i dane dostosowały się do sztywnego modelu bazy danych. Baza danych jest ostateczną wyrocznią jakości danych. Natomiast w modelu dokumentowym to baza danych dostosowuje się do struktury danych aplikacji. Aplikacja ma decydujący głos co w bazie danych się znajdzie. Dotyczy także języka zapytań. Język SQL ściśle związany z bazami relacyjnymi w samej swojej nazwie ma 'strukturalny’. MongoDB posługuje się znacznie prostszym własnym językiem notacją przypominającym język programowania. Trzeba pamiętać, że jest to język także znacznie uboższy w funkcjonalność.
Można sobie wyobrazić, że model dokumentowy jest mokrym snem programisty. Większość współczesnych aplikacji i tak operuje danymi w formacie JSON, więc bez żadnych modyfikacji dane te mogą być umieszczone w dokumentowej bazie danych. Zostaną wstawione do bazy danych nawet gdy ich struktura się zmieni. Wtedy jest to problem motoru bazy danych, a nie twórcy aplikacji, jak obsłuży niejednorodną strukturę danych. Dzięki temu programiści moga skupić się na lepszym poznaniu swojego ulubionego języka programowania i szybciej dostarczać nową funkcjonalność klientom. Nie muszą poświęcać czasu na naukę czegoś tak różnego od programowania obiektowego jak relacyjny model danych. A także nie muszą rozwijać swoich umiejętności manipulowania danymi w bazie danych ponad CRUD.
Z drugiej strony ludzie dla których dokładność danych jest bardzo ważna preferują sztywne struktury modelu relacyjnego. Wszystko co wiąże się z finansami i odpowiedzialnością prawną wymaga przestrzegania określonych reguł przychowywania i przetwarzania danych. Dlatego gdy patrzysz na opis stanu magazynowego na stronie internetowej sklepu akceptujesz określenia dużo lub mało. Ale gdy oglądasz stan swojego konta bankowego to wolisz widzieć kwotę określoną co do grosza.
Trzeba pamiętać, że zdjęcie z barków programistów wymagania nauczenia się modelowania danych w bazie danych oraz efektywnego korzystania z motoru bazy danych oznacza, że to motor bazy danych musi ogarnąć niejednorodne dane. Zrobi to za cenę większej konsumpcji zasobów. Czyli mocy obliczeniowej i nośników danych. Warto przemyśleć co jest bardziej opłacalne. Czy zakup lepiej wyedukowanych i bardziej doświadczonych programistów czy zasobów komputerowych. Jest to decyzja o charakterze strategicznym. O ile można dostrzec braki wśród dobrych programistów o tyle dostawcy chmury reklamują się nieograniczonymi zasobami. Mam także wrażenie, że firmom jakoś łatwiej zapłacić za sprzęt niż za człowieka. Jakie są Twoje wrażenia?
Producenci motorów wyrosłych na modelu relacyjnym implementują obsługę nierelacyjnych modeli. W tym samym czasie producent MongoDB implementuje w swoim motorze funkcjonalności wspierające jakość danych. Język SQL wzbogacany jest o możliwości operowania danymi nierelacyjnymi, a MongoDB pomaga przetłumaczyć komendy SQL na swój natywny język. Moim zdaniem motor nierelacyjny powinien być używany jedynie wtedy gdy w Twoich danych nie ma żadnych relacyjnych. Gdy masz choć trochę relacyjnych danych wtedy wybierz relacyjny multimodel.
Jak widać w statystykach popularności i wydatków każdy model ma swoja niszę. Ważne aby dobrać odpowiedni do Twoich potrzeb, a nie możliwości, sympatii czy mody. Według mnie kluczowa jest decyzja gdzie ma być główny ciężar odpowiedzialności za jakość danych.
To piąta część cyklu o ekosystemie bazy danych.
Poprzednia: 9 bazodanowych VIPów.
Kolejna część cyklu: Jeden SQL by wszystkim zarządzać.



