
Wstęp
Czasem zdarzy się tak, że deweloperzy popełnią jakąś aplikację i już ich nie ma. Czasem zdarzy się tak, że sukces aplikacji przerośnie ambicje jej pomysłodawców. Czasem zdarzy się tak, że użytkownicy aplikacji nie zadbają o cykl życia danych. Zatroszczą się jedynie o ich ładowanie i wydajne przetwarzanie. W związku z czym danych przybywa, przybywa i przybywa aż wydajne przetwarzanie jest coraz mniej wydajne. Szczególnie gdy schemat i komendy SQL nie są optymalne. Wtedy najczęściej kontaktują się z administratorami baz danych aby ci zerknęli na bazę danych bo ta nie pracuje wydajnie.
Zespół wsparcia użytkowników aplikacji zlecił mi poprawę wydajności współpracy z jedną z tabel ich bazy danych. Oto pierwszy przykład z życia oraklowego debeowca.
Środowisko
Tabela ma 7TB. Nie ma klucza głównego. Spartycjonowana jest według listy wartości kolumny data. Z angielska list partitions. Każda partycja przechowuje dane z jednego dnia, a jest ich ponad 1500. Rozmiar partycji waha się od jednego do czterech GB. Kolumna data jest typu DATE.
CREATE TABLE t (
"data" DATE NOT NULL
,"źródło" VARCHAR2(20 CHAR) NOT NULL
[
Jakieś 20 innych kolumn
]
) PARTITION BY LIST ("data")
(
PARTITION "P20170101" VALUES (DATE'2017-01-01')
,PARTITION "P20170102" VALUES (DATE'2017-01-02')
[
Ponad 1500 innych partycji
]
)
Jak zapewne pamiętasz typ DATE w Oracle, oprócz daty, zawiera także czas z sekundową dokładnością. Jeśli czasu do bazy danych nie wstawisz to Oracle samodzielnie ustawi czas na północ. Czyli 00:00:00.

Na kolumnie data założony jest indeks lokalny. To znaczy: indeks spartycjonowany jest identycznie jak tabela. Czyli każdej partycji tabeli odpowiada partycja indeksu.
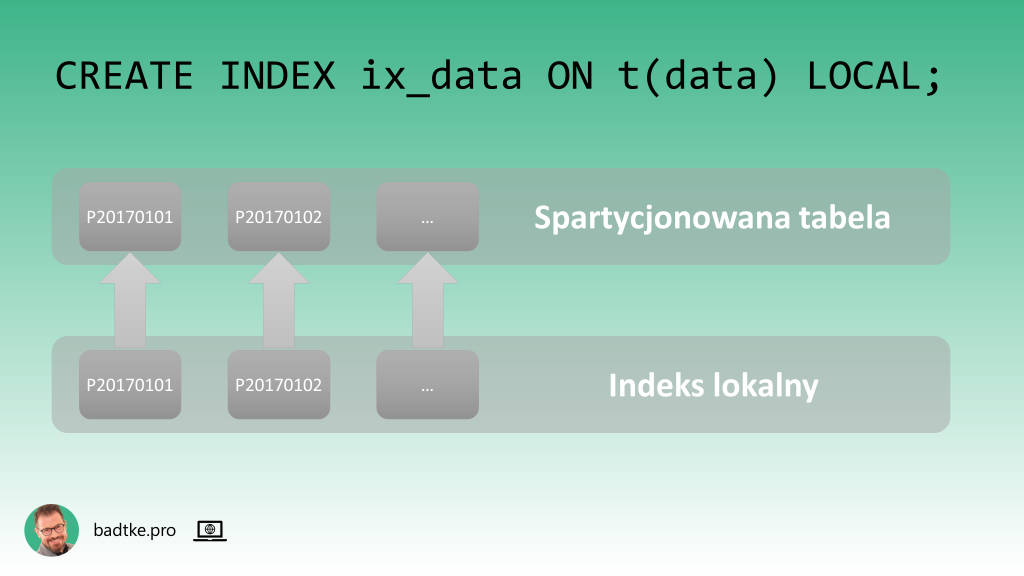
Zapytania
Od czego zacząć analizę wydajności?
Ja zacząłem od znalezienia zapytań używających tej tabeli. W tym celu odpytałem widok V$SQL. Wyróżniłem dwa rodzaje zapytań:
- zapytania filtrujące dane z tabeli t jedynie na podstawie wartości kolumny data. To 10% zapytań do tej tabeli.
- zapytanie filtrujące dane z tabeli t na podstawie wartości kolumn data i źródło. To 90% wszystkich zapytań.

Hmm, nic niezwykłego. Nie specjalnie jest co stroić. Żadnych złączeń, podzapytań czy choćby funkcji na kolumnie. Każde z zapytań może użyć indeksu na kolumnie data.
Plany wykonania
Może warto sprawdzić plan wykonania?
Część zapytań używa indeksu, a część nie używa. Niemniej każde poprawnie rozpoznaje partycje i dokonuje tzw. partition pruning. Czyli ogranicza czytanie tabeli jedynie do partycji zawierającej potrzebne dane.
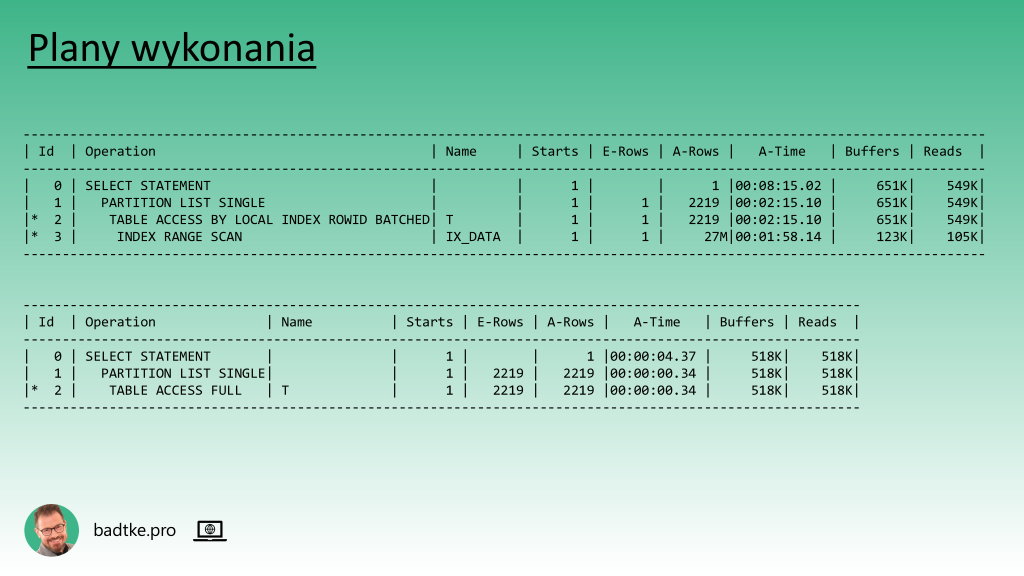
Zerkam na statystyki i widzę, że mniej więcej połowa partycji w ogóle nie ma policzonych.
Zwróć uwagę na kolumny E-Rows i A-Rows w pierwszym planie wykonania. Znaczą odpowiednio estimated i actual. Czyli E-Rows to ilość wierszy, której optymalizator spodziewa się na podstawie statystyk, a A-Rows to faktyczna ilość odczytanych wierszy.
Jak sądzisz dlaczego jest rozbieżność? Dlaczego nie ma rozbieżności w drugim planie wykonania?
Masz rację, nie ma aktualnych statystyk dla indeksu. Daj znać w komentarzu czy chcesz wiedzieć jak uzyskać te dane w planie wykonania.
Dygresja: dlatego robi różnicę czy oglądasz plan wykonania wygenerowany komendą explain plan czy plan faktycznie uruchomionego zapytania.
Parsowanie
Dodatkowo zapytania nie używają zmiennych wiązanych. Każde używa literałów. Czyli każde zapytanie musi zostać sparsowane jako nowe. Z angielska hard parse. Innymi słowy dla każdego zapytania musi zostać opracowany plan wykonania.
Kosztowne podobnie jak kompilacja programu w Java przed każdym jego wykonaniem.

To może być przyczyną, że mimo, iż zapytania są niemal identyczne optymalizator raz uznaje, że warto użyć indeksu, a innym razem, że nie warto.
Optymalizacja
Decyduję, że trzeba przeliczyć brakujące statystyki. Co jeszcze można zrobić aby skrócić czas wykonania zapytań?
Jeśli nie można niczego zoptymalizować w komendzie SQL to może da się zoptymalizować schemat tabeli? Może warto przebudować istniejący indeks i dołożyć kolumnę źródło?
CREATE INDEX ix_data_źródło on t(data, źródło) LOCAL;
Wtedy mogłyby go używać zapytania wyszukujące dane jedynie wg daty, a te wyszukujące wg daty i źródła skorzystałyby dodatkowo. W takim przypadku oczywistym jest, że data musi być na pierwszej pozycji w indeksie.
Jakiej czynności jeszcze nie wykonałem, a która jest bardzo ważna przy strojeniu SQL?
Rozkład danych
Masz rację z pewnością warto zerknąć na rozkład danych.
Liczę ile każde źródło ma wartości w kilku wybranych partycjach.
SELECT "źródło", count(*) FROM t PARTITION(P20170101) GROUP BY "źródło";
Widzę, że źródło ma kilkadziesiąt unikalnych wartości. Ich ilość nie jest taka sama w każdej partycji. Ilość rekordów dla poszczególnych źródeł waha się od kilku rekordów do kilkunastu milionów rekordów w każdej partycji.
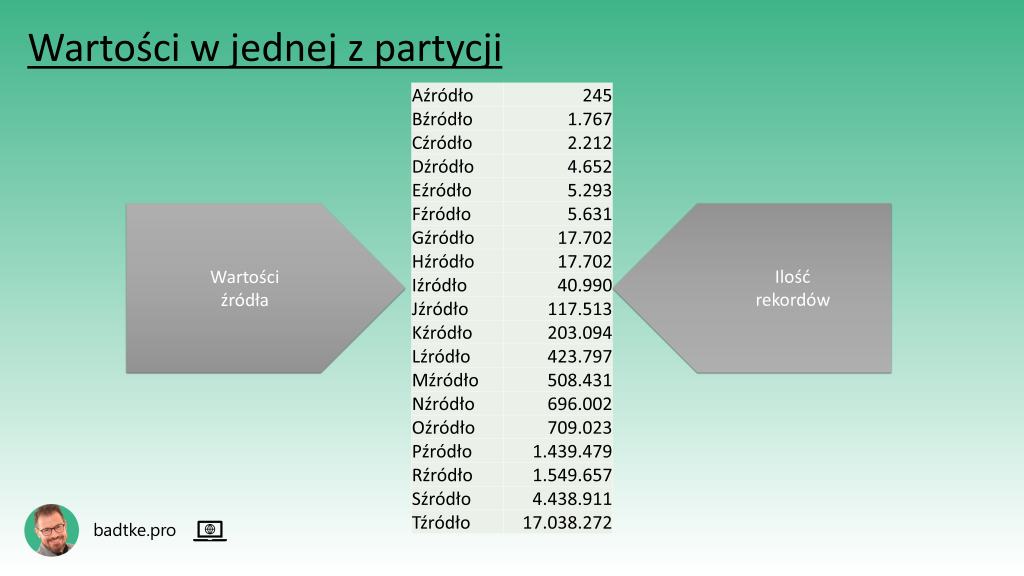
Tabela zawiera dane od pierwszego 2016.01.01 i codziennie przyrasta o nową parogigową partycję.
Kropka
W tym momencie stawiam kropkę. Kropka jest po napisie 'ciąg dalszy nastąpi’. Na zakończenie tej części powiem jedynie, że żadna z wcześniej wymienionych zmian nie przyniosła skrócenia czasu wykonania komend SQL.
Daj znać w komentarzach co sądzisz o moim podejściu i pomysłach. Skomentuj co według Ciebie mogę jeszcze zrobić aby poprawić wydajność pokazanych zapytań.
Mam swoje pomysły, które będę testował w kolejnych dniach. W następnej części, która ukaże się za tydzień, pokażę jakie pomysły przetestowałem i jaki odniosły skutek.
Dziękuję za zainteresowanie i zapraszam na kolejny materiał.
Wiesz co trzeba zrobić aby go nie przegapić.




halo halo my tu czekamy 🙂
Łap jeszcze ciepły: https://badtke.pro/z-zycia-wziete-1-1-strojenie-sql/