
Czy to, że typ CHAR jest stałej długości, a typ VARCHAR zmiennej to jedyna różnica? Co wziąć pod uwagę definiując typ kolumny? Artykuł dotyczy także VARCHAR2 w Oracle.
Materiał dostępny także w formie wideo:
Podstawowe 2 różnice CHAR i VARCHAR
Różnica, która najbardziej rzuca się w oczy jest taka, że łańcuch znaków umieszczony w kolumnie typu CHAR składa się zawsze z tej samej ilości znaków. Gdy wstawisz łańcuch krótszy, niż zdefiniowana długość, motor bazy danych dopełni go spacjami do zdefiniowanej długości. Z prawej strony.
Na przykład:
wstawiasz 'Marcin do VARCHAR(9) to na dysku znajdzie się 'Marcin’
wstawiasz 'Marcin’ do CHAR(9) to na dysku znajdzie się 'Marcin ’
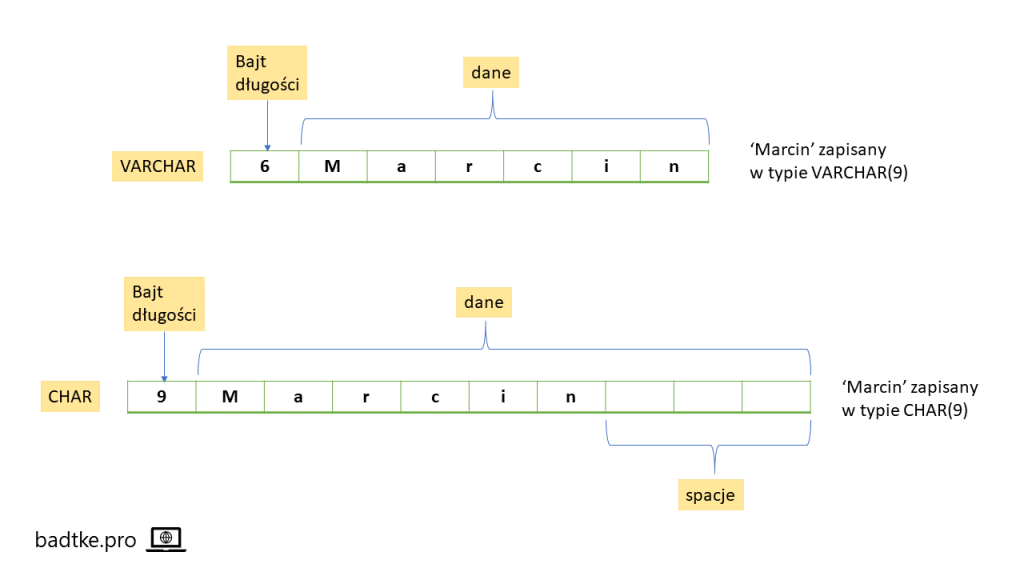
Drugą ważną różnicą jest, maksymalna pojemność. Na przykład w Oracle typ CHAR może pomieścić maksymalnie 2000 bajtów, a typ VARCHAR2 4000 bajtów. Typ VARCHAR w Oracle jest aliasem do VARCHAR2. Niemniej producent zaleca używanie VARCHAR2.
W SQL Server oba typy mieszczą maksymalnie 8000 bajtów.
W PostgreSQL 10485760 znaków dla obu typów.
W MySQL CHAR pomieści 255 znaków, a VARCHAR 65535 znaków.
Zwraca uwagę, że różni producenci motorów używają różnych jednostek do określania wielkości typu. Jedni używają bajtów inni znaków. Wskazywanie wielkości typu przy pomocy znaków jest zgodne ze standardem ANSI języka SQL. Niemniej dopóki używasz jednobajtowego kodowania znaków nie ma to znaczenia.
Składowanie na dysku
Popularna opinia mówi, że w przypadku typu CHAR motor bazy danych czerpie informacje o długości łańcucha znaków z definicji tabeli/kolumny. Bo jest taka sama dla wszystkich rekordów w tabeli.
Ta sama opinia głosi, że typ VARCHAR zajmuje od dwóch do czterech bajtów więcej niż łańcuch znaków. W dodatkowych bajtach przechowywana jest długość łańcucha znaków.
Jak jest naprawdę?
W SQL Server do każdego łańcucha znaków dodawane są 2 bajty określające jego długość. Niezależnie od tego czy to typ CHAR czy VARCHAR.
W PostgreSQL limitem jest 126 bajtów. Tak BAJTÓW. Gdy łańcuch znaków nie przekracza 126 bajtów jego długość kodowana jest na jednym dodatkowym bajcie. Gdy długość łańcucha znaków przekracza 126 bajtów jego długość kodowana jest na czterech bajtach. Niezależnie czy to CHAR czy VARCHAR.
Długość łańcucha znaków VARCHAR, w MySQL, kodowana jest na jednym dodatkowym bajcie. Gdy długość nie przekracza 255 BAJTÓW. Gdy przekracza, długość kodowana jest na dwóch bajtach. Typ CHAR nie ma dodatkowego bajtu.
Oracle używa 1-3 bajtów do zakodowania długości łańcucha znaków. Niezależnie od tego czy to typ CHAR czy VARCHAR2. Zależy jedynie od długości łańcucha. Łańcuchy do 250 bajtów długości zużyją dodatkowo jeden bajt, dłuższe trzy bajty, na przechowanie długości.
Wstawianie wartości
Jesteśmy przyzwyczajeni, że do kolumny o określonym typie możemy wstawić jedynie wartości z określonego zakresu. Na przykład definiując kolumnę jako CHAR(9) możemy do niej wstawić jedynie 9 znaków. Czy tak jest naprawdę? Sprawdź:
CREATE TABLE t (kolumna_char char(9), kolumna_varchar varchar(9));
INSERT INTO t (kolumna_char, kolumna_varchar) VALUES ('Marcin ','Marcin');
INSERT INTO t (kolumna_char, kolumna_varchar) VALUES ('Marcin','Marcin ');
PostgreSQL obcina końcowe spacje, wstawianej wartości, przekraczające zdefiniowaną dla kolumny długość. Zarówno dla typu CHAR jak i VARCHAR.
Innymi słowy PostgreSQL przyjmie łańcuch znaków dłuższy niż zdefiniowana kolumna, ale odrzuci końcowe spacje przekraczające długość kolumny. Jest to zachowanie zgodne ze standardem SQL.
Oracle tego nie robi dla żadnego z typów. W Oracle, dla obu typów, dostaniesz błąd ORA-12899.
Przyrównywanie do literałów
Dopóki porównujesz typ CHAR do CHAR, a VARCHAR do VARCHAR to nie ma problemu. Nawet w przypadkach gdy porównujesz literał bez spacji do CHAR też nie ma problemu. Motor bazy danych dokona niejawnej konwersji. Zobacz korzystając z tabeli z poprzedniego akapitu:
SELECT * FROM t WHERE kolumna_char='Marcin';
kolumna_char | kolumna_varchar
-------------+-----------------
Marcin | Marcin
Marcin | Marcin
(2 rows)SELECT * FROM t WHERE kolumna_varchar='Marcin';
kolumna_char | kolumna_varchar
-------------+-----------------
Marcin | Marcin
(1 row)Dlaczego przyrównanie literału do kolumny CHAR zwróciło dwa rekordy, a do kolumny VARCHAR jeden?
Dla typu VARCHAR końcowe spacje są znaczące. PostgreSQL usłużnie obciął Ci spacje przekraczające długość kolumny, podczas wstawiania rekordów, ale reszta została wstawiona. W związku z tym, dla typu VARCHAR, wartości 'Marcin’ i 'Marcin ’ są różne.
Końcowe spacje, w typie CHAR, są zarządzane przez motor. Podczas wstawiania dokłada ich odpowiednią ilość, a podczas wybierania obcina. Dlatego wartości 'Marcin ’ i 'Marcin’ dla typu CHAR są takie same. Niemniej w bloku bazodanowym końcowe spacje istnieją.
Dla typu VARCHAR motor bazy danych uważa, że wiesz co robisz. Jeśli wstawiasz tam spacje to znaczy, że są dla Ciebie ważne.
Tak samo zachowa się Oracle.
Porównanie kolumn typów CHAR i VARCHAR w PostgreSQL zadziała niezależnie od ilości końcowych spacji:
SELECT * FROM t WHERE kolumna_char=kolumna_varchar;
kolumna_char | kolumna_varchar
-------------+-----------------
Marcin | Marcin
Marcin | Marcin
(2 rows)To samo zapytanie w Oracle zwróci tylko jeden rekord, ponieważ motor Oracle nie dokona niejawnej konwersji typów.
W Oracle, aby porównanie CHAR=VARCHAR2 było prawdziwe, musisz dopełnić VARCHAR2 spacjami:
SELECT * FROM t WHERE kolumna_char=rpad(kolumna_varchar,9);
Lub obciąć spacje z CHAR:
SELECT * FROM t WHERE trim(kolumna_char)=kolumna_varchar;
Wydajniej działa dopełnianie spacjami niż użycie trim na kolumnie. Funkcja użyta na kolumnie uniemożliwi motorowi skorzystanie z indeksu. Gdyby na kolumnie indeks był zbudowany.
Przyrównywanie do zmiennych wiązanych
W przypadku zmiennych wiązanych w PostgreSQL, gdy zmienna jest typu CHAR, ale porównywana z kolumną VARCHAR zwrócone zostaną 2 rekordy:
prepare char_zw(char(9)) as select * from t where kolumna_varchar=$1;
execute char_zw('Marcin');
kolumna_char | kolumna_varchar
-------------+-----------------
Marcin | Marcin
Marcin | Marcin
(2 rows)Końcowe spacje potraktowane zostaną jako nieistotne. Mimo, że w jednym wierszu kolumna_varchar ma jawnie wstawione spacje.
Natomiast porównując zmienną wiązaną VARCHAR do kolumny VARCHAR końcowe spacje nie zostaną zignorowane:
prepare varchar_zw(varchar(9)) as select * from t where kolumna_varchar=$1;
execute varchar_zw('Marcin');
kolumna_char | kolumna_varchar
-------------+-----------------
Marcin | Marcin
(1 row)execute
varchar_zw('Marcin ');
kolumna_char | kolumna_varchar
-------------+-----------------
Marcin | Marcin
(1 row)Zawsze zwrócony został tylko jeden wiersz. Ten w którym wartość w kolumna_varchar była równa wartości zmiennej wiązanej tego samego typu. Końcowe spacje zostały potraktowane jako znaczące.
W Oracle wygląda to nieco inaczej:
variable char_zw char(9) exec :char_zw := 'Marcin'; SELECT * FROM t WHERE kolumna_char=:char_zw;
KOLUMNA_CHAR KOLUMNA_VARCHAR
--------------- ---------------
Marcin Marcin
Marcin Marcin Przyrównując zmienną wiązaną typu CHAR i kolumnę typu CHAR spacje zostają potraktowane jako nieważne. Natomiast przyrównując zmienną wiązaną typu CHAR do kolumny typu VARCHAR spacje traktowane są jako istotne.
Podobnie w przypadku zmiennej wiązanej typu VARCHAR:
variable varchar_zw varchar2(9) exec :varchar_zw := 'Marcin'; SELECT * FROM t WHERE kolumna_char=:varchar_zw;
no rows selectedOracle nie zwrócił żadnego wiersza, ponieważ w kolumnie CHAR znajdują się wartości 'Marcin ’, które przyrównano do zmiennej wiązanej 'Marcin’. Podobnie jak w przypadku porównywania kolumn należałoby zmienną wiązana dopełnić spacjami. Lub obciąć spacje przy pomocy trim wartościom w kolumnie CHAR.
SELECT * FROM t WHERE kolumna_varchar=:varchar_zw;
KOLUMNA_CHAR KOLUMNA_VARCHAR
--------------- ---------------
Marcin Marcin Oracle zwrócił jeden wiersz. Drugi zawiera łańcuch znaków 'Marcin ’, który nie równa się zmiennej wiązanej zawierającej 'Marcin’.
Wydajność
Testowałem wykonanie operacji JOIN na kolumnach typu NUMBER, CHAR i VARCHAR2. Stworzyłem tabelę zawierającą 630496 wierszy:
CREATE TABLE t (id_num number, id_vchar varchar2(38), id_char char(38), num_val number); INSERT INTO t (id_num,id_varchar, id_char, num_val) SELECT object_id, to_char(object_id),to_char(object_id),object_id FROM all_objects;
Co spowodowało wypełnienie tabeli wartościami od 2 do 479279. Czyli liczbami o ilości cyfr od 1 do 6.
Następnie 3x wykonałem każde z zapytań:
SELECT sum(t1.num_val+t2.num_val) FROM t t1 LEFT JOIN t t2 ON t1.id_num=t2.id_num; SELECT sum(t1.num_val+t2.num_val) FROM t t1 LEFT JOIN t t2 ON t1.id_char=t2.id_char; SELECT sum(t1.num_val+t2.num_val) FROM t t1 LEFT JOIN t t2 ON t1.id_vchar=t2.id_vchar;
Czasy wykonania zapytania używającego, w JOIN, kolumn typu NUMBER wynosił od 10 do 12 sekund.
JOIN kolumn typu CHAR(38) wykonywał się pomiędzy 12, a 20 sekund.
Natomiast JOIN przy użyciu VARCHAR2(38) trwał od 12 do 19 sekund.
Co pokazuje, że typ NUMBER jest o ok 20% wydajniejszy w stosunku do typów znakowych. Podobne wyniki typów znakowych wskazują na faktyczny brak różnic pomiędzy nimi. CHAR jest dopełnionym spacjami VARCHAR2.
Rozmiary kolumn zostały dobrane tak aby pomieścić tę samą ilość znaków.
Identyczny test dla PostgreSQL dał wyniki:
JOIN kolumn numeric 278ms – 281ms
JOIN kolumn varchar 244ms – 252ms
JOIN kolumn char 337ms – 345ms
Co pokazuje, mniejszą o ok 25%, wydajność CHAR w stosunku do VARCHAR. A w stosunku do NUMERIC o ponad 15%.
Tabela testowa została utworzona komendą:
CREATE TABLE t (id_num numeric, id_vchar varchar(38), id_char char(38), num_val numeric);
Wypełniona została liczbami składającymi się z od jednej do sześciu cyfr.
Indeksowanie
Dla unikalnego indeksu stworzonego na kolumnie typu CHAR wartości 'Marcin’ i 'Marcin ’ są duplikatami. Próbując je wstawić dostaniesz błąd.
Indeks zbudowany na kolumnie typu CHAR będzie większy niż zbudowany na kolumnie VARCHAR z identycznymi wartościami. Co nie dziwi biorąc pod uwagę dopełniające spacje.
W moim przypadku, dla testowej tabeli, indeks zbudowany na kolumnie CHAR jest ponad dwa razy większy niż na kolumnie VARCHAR. Należy pamiętać, że kolumny mieszczą 38 znaków. Z czego tylko CHAR wypełnia całe 38.
Gdy zmieniłem wielkość kolumn na 6 i wypełniłem danymi:
CREATE TABLE t2 (char_kol char(6), vchar_kol varchar(6), num_kol number(6)); INSERT INTO t2 (char_kol, vchar_kol, nul_kol) SELECT substr(to_char(num_val,'099999'),0,6), substr(to_char(num_val,'099999'),0,6), num_val FROM t;
czyli kolumny znakowe zostały pozbawione nieznaczących końcowych spacji. Indeksy zbudowane na kolumnach:
CREATE INDEX ch_ix ON t2(char_kol); CREATE INDEX vch_ix ON t2(vchar_kol); CREATE INDEX n_ix ON t2(num_kol);
różniły się wielkością na korzyść typu numerycznego w Oracle. Był 50% mniejszy niż indeksy zbudowane na kolumnach znakowych. Indeksy zbudowane na CHAR i VARCHAR miały zbliżony rozmiar.
W PostgreSQL, również indeksy na CHAR i VARCHAR miały podobną wielkość. Natomiast indeks na kolumnie numerycznej był ponad 3x większy.
Modyfikowanie kolumny typu CHAR
Oracle pozwoli skrócić kolumnę VARCHAR2 zmniejszając ilość dopuszczalnych znaków. Na przykład zamieniając typ VARCHAR2(11) na VARCHAR2(9). O ile żaden łańcuch znaków nie jest dłuższy niż 9.
W kolumnie typu CHAR(11) wszystkie łańcuchy znaków są długości 11. Próba modyfikacji typu z CHAR(11) na CHAR(9), w Oracle, zaowocuje błędem: ORA-01441. Nawet gdy ostatnie 2 znaki to spacje. Konieczne będzie przepisanie tabeli.
Podobnych przeszkód nie stawia PostgreSQL. W tym motorze możesz zmodyfikować zarówno typ CHAR jak i VARCHAR na krótszy. Pod warunkiem, że na końcu nie ma znaków innych niż spacja.
Podsumowanie
Oprócz MySQL typ CHAR nie ma przewag w składowaniu na dysku. Jeśli łańcuch znaków wypełnia go w całości, zajmuje dokładnie tyle samo bajtów co umieszczony w VARCHAR.
Jeśli nie wykorzystujesz całości CHAR wtedy motor bazy danych dopełni łańcuch znaków spacjami. Przez co zużyjesz więcej przestrzeni dyskowej niż korzystając z VARCHAR.
Motory baz danych dopisują i obcinają końcowe spacje dla wartości typu CHAR za Ciebie. Nie wszystkie robią to w ten sam sposób. Daje to narzut na ich dopisanie oraz obcinanie spacji. Również Ty musisz pamiętać jak dany motor zachowa się w konkretnej sytuacji. Co utrudnia pracę z różnymi motorami.
Gdy przyrównujesz wartości różnych typów – CHAR do VARCHAR – będziesz napotykać problemy z końcowymi spacjami. Różne motory baz danych nie zawsze traktują końcowe spacje zgodnie z intuicją. Na dodatek inaczej traktowane są wartości przekazywane jako literały, a inaczej jako zmienne wiązane.
Typ CHAR gorzej niż VARCHAR i NUMBER/NUMERIC performuje. Warto o tym pamiętać wybierając typ danych dla kolumny, która będzie często używana w JOIN.
Niektóre motory pozwalają na modyfikację struktury tabeli i skrócenie typu CHAR o nieznaczące spacje. Inne nie pozwolą na tę operację. Z VARCHAR nie ma takich problemów.
Wg mnie typ CHAR nie ma zalet. Wprowadza niepotrzebne zamieszanie i narzut na obsługę końcowych spacji nie dając nic w zamian. Nawet używanie go dla danych, które mają zawsze taką samą długość, jak tak/nie, kod pocztowy, NIP czy PESEL, ma przewagę jedynie w MySQL. Eliminuje jeden bajt potrzebny na przechowywanie długości łańcucha znaków. Co dla miliona rekordów oznacza 1 megabajt powierzchni dyskowej.
A dlaczego nie przechowywać tego typu danych w typach numerycznych?
Prowadzę szkolenia i kursy z podstaw SQL. Sprawdź ofertę moich kursów SQL.




Cały czas żyłem w przekonaniu, że jedyna faktyczna różnica między tymi typami to ta opisana na początku wpisu. Dzięki za tak pogłębioną analizę tematu! 🙂
Dzięki za komentarz. Miło mi.