
Wstęp
Wstawianie zbiorów danych pojedynczymi komendami INSERT jest nieoptymalne. Tutaj link do mojego artykułu jak dodawać pojedyncze rekordy.
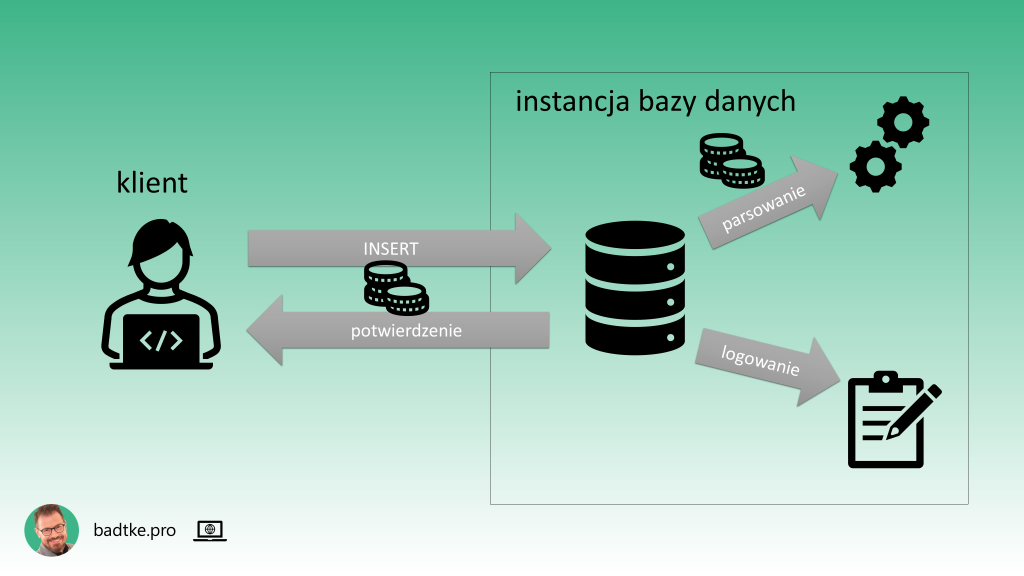
Na każdy INSERT składa się: przesłanie komendy od klienta do instancji bazy danych, parsowanie komendy, zapis informacji o transakcji do logu transakcyjnego, przesłanie informacji od instancji do klienta czy dodanie rekordu się powiodło czy nie.
Komunikacja sieciowa jest kosztowna. Mimo, że sieci są coraz szybsze w dalszym ciągu stanowią najwolniejszy element systemu komputerowego. Bardzo kosztowne jest także parsowanie komendy SQL przez motor bazy danych.
Zaprezentuję 4 sposoby na ograniczenie tych kosztów i zwiększenie szybkości wstawiania rekordów do tabeli. Tym bardziej przydatne jeśli wstawiasz zbiory danych regularnie.
Transakcja
Najprostszym sposobem na optymalizację wstawiania wielu rekordów do bazy danych jest zamknięcie wielu operacji INSERT w jedną transakcję.
Trzeba pamiętać, że każda, wydana przez Ciebie motorowi bazy danych, komenda SQL jest dla motoru transakcją. Jej początek i koniec często sa dla Ciebie niejawne i określane przez motor bazy danych oraz używanego przez Ciebie klienta. Świadomość tych ustawień jest mniej istotna dopóki jedynie czytasz dane. Staje się kluczowa gdy je modyfikujesz. Na przykład wstawiasz. Zachęcam, więc do sprawdzenia ustawienia parametru autocommit w Twoim kliencie.
Oracle idzie Ci na maksa na rękę. Za Ciebie rozpoczyna transakcję razem z pierwszą wydaną komendą SQL. Teraz piłka jest po Twojej stronie. Wydajesz tyle komend INSERT ile masz odwagę. Gdy odwaga się wyczerpie wydajesz komendę COMMIT.
INSERT INTO t VALUES ( 1 ); INSERT INTO t VALUES ( 2 ); INSERT INTO t VALUES ( 3 ); COMMIT;
Wychodząc z sqlplus wydajesz ją niejawnie. Innymi słowy sqlplus, gdy z niego wychodzisz, zatwierdza transakcje za Ciebie. Gdy sqlplus zakończy pracę anormalnie wtedy transakcja jest wycofywana.
W innych motorach baz danych i klientach może być inaczej. Daj znać jak jest w Twoim.
Na porzykład taki psql dla Postgresa, w ustawieniach domyślnych, zatwierdza każdą transakcję SQL za Ciebie.
Jeśli chcesz zamknąć wiele komend INSERT w jedną transakcję jawnie użyj komendy BEGIN. Następnie INSERTy i na koniec COMMIT. W ten sposób w dalszym ciągu każda komenda INSERT jest osobno przesyłana do instancji, parsowana i zapisywana w logu transakcyjnym, ale ich zatwierdzenie lub wycofanie jest hurtowe.
BEGIN; INSERT INTO t VALUES (1); INSERT INTO t VALUES (2); INSERT INTO t VALUES (3); COMMIT;
Trzeba pamiętać, że transakcja to wszystko albo nic. Albo wszystkie rekordy znajdą się w bazie danych, albo żaden.
Język proceduralny
Język proceduralny PL/SQL motoru Oracle obsługiwany jest innymi mechanizmami niż język SQL. Możesz wykorzystać jego funkcjonalność i wstawiać rekordy przy pomocy bloków PL/SQL.
Wystarczy gdy serię komend INSERT rozpoczniesz słowem kluczowym BEGIN. Uwaga: bez średnika. A zakończysz słowem kluczowym END ze średnikiem i ukośnikiem.
BEGIN INSERT INTO t VALUES ( 1 ); INSERT INTO t VALUES ( 2 ); INSERT INTO t VALUES ( 3 ); END; / COMMIT;
Jest to tak zwany anonimowy blok PL/SQL. Dzięki temu do motoru bazy danych przesyłany jest cały blok, a nie poszczególne komendy INSERT.
Cały blok jest parsowany i zatwierdzany. Informację o rezultacie wykonania dostajesz raz zamiast dla każdej komendy INSERT osobno. Oszczędzasz na komunikacji sieciowej i parsowaniu.
Podobnie gdy wykorzystasz język proceduralny PL/pgSQL dostępny w Postgresie. Tutaj aby instancja wykonała anonimowy blok PL/pgSQL musisz poprzedzić go słowem kluczowym DO a blok otoczyć apostrofami.
DO $$ BEGIN INSERT INTO t VALUES (1); INSERT INTO t VALUES (2); INSERT INTO t VALUES (3); END; $$; COMMIT;
Według mnie użycie dwóch znaków dolara do zaznaczenia początku i końca bloku jest bardziej czytelne i wygodniejsze. Nie trzeba maskować użytych w bloku apostrofów. Jak sądzisz?
Jeśli po COMMIT dostaniesz komunikat 'WARNING: there is no transaction in progress’ to znaczy, że Twój klient ma włączony autocommit i zatwierdził transakcję za Ciebie.
Użycie języka proceduralnego to także transakcja. Czyli albo wstawią się wszystkie rekordy albo żaden.
Zmienne wiązane
Z uwagi na to, że Java jest najlepszym językiem programowania to być może, zamiast wykorzystania funkcjonalności motoru bazy danych, masz w aplikacji pętelkę, która pracowicie dodaje rekord po rekordzie do bazy danych. W takim przypadku zwróć uwagę czy wykorzystuje zmienne wiązane.
Tworząc zapytanie zamiast wstawiania literałów wstawiasz znaki zapytania. Czyli oznaczasz pozycję na którą ma zostać podstawiona wartość. Jest to tak zwany placeholder. Wartość przekazujesz jedną z rodziny funkcji set. W tym przypadku jest to setInt ponieważ wstawiam liczby całkowite.
PreparedStatement pstat = connection.prepareStatement("INSERT INTO t ( c ) VALUES ( ? )");
for (int i = 0; i < 5; i++) {
pstat.setInt( 1, i);
ResultSet rset = pstat.executeQuery();
}
Dzięki temu kwerenda, przez motor bazy danych, zostanie sparsowana raz. Do kolejnych wywołań zostaną jedynie podstawione kolejne wartości. Oszczędzasz na parsowaniu.
Parsowanie SQL to coś takiego jak kompilacja kodu źródłowego. Na przykład Javy. Nie chcesz kompilować swojego kodu przed każdym wykonaniem, prawda?
W zależności od ustawienia autocommit Twojego klienta, każde wykonanie komendy może być transakcją. Dlatego, w przypadku awarii, część rekordów ze zbioru może zostać wstawiona, a część nie.
Zmienne wiązane możesz używać także w innych językach programowania, tak w PHP także, jak i językach proceduralnych motorów baz danych. Na przykład PL/SQL czy PL/pgSQL.
Value constructor
W przypadku komendy INSERT value constructor umożliwia wypisanie wielu zestawów wartości zamiast jednego. Każdy zestaw wartości otaczasz nawiasami okrągłymi. Jeden zestaw od drugiego oddzielasz przecinkiem.
INSERT INTO t (kolumna_numeryczna) VALUES ( 1 ), ( 2 ) , ( 3 );
Dostępne w każdym wiodącym motorze bazy danych. W Oracle od wersji 23c.
Value constructor może być używany w różnych komendach SQL. Nie tylko w INSERT. I jest ustandaryzowany przez ANSI, więc przenaszalny. Niemniej ma swoje ograniczenia. Na przykład SQL Server dozwala do 1000 zestawów wartości.
Jak jest w Twoim motorze?
Temat jest tak szeroki, że zasługuje na osobny materiał.
Dzięki użyciu value constructor oszczędzasz na komunikacji sieciowej i parsowaniu komendy. Wstawisz wszystkie rekordy lub żadnego w zależności od powodzenia operacji.
Oracle pre 23c
Oracle do wersji 23c ignorował value constructor. Niemniej dysponował, bardzo podobną w działaniu, składnią. Po bliższym poznaniu nawet bardziej elastyczną.
INSERT ALL INTO t ( c ) VALUES(1) INTO t ( c ) VALUES(2) INTO t ( c ) VALUES(3) SELECT * FROM dual;
Komendą jest INSERT ALL. Po niej wypisujesz klauzule INTO. Zbudowane są identycznie jak dla komendy INSERT INTO. Czyli muszą zawierać nazwę tabeli, listę kolumn w nawiasach okrągłych, słowo kluczowe VALUES i listę wartości w nawiasach okrągłych. Na końcu musi być SELECT.
Pierwotnie komenda powstała by wesprzeć migrację danych z jednej tabeli do wielu. Co możesz wykorzystać. Klauzulą INTO możesz kierować dane do różnych tabel.
INSERT ALL INTO t1 ( t1_id, c_num ) VALUES ( 111, 1 ) INTO t2 ( t2_id, c_char ) VALUES ( 22, 'M' ) INTO t3 ( t3_id, c_date ) VALUES ( 3, DATE'1972-05-20' ) SELECT * FROM dual;
Możesz dodać także warunki po spełnieniu których konkretna klauzula INTO zadziała. Ale to temat na osobny materiał podobnie jak użycie FIRST zamiast ALL.
INSERT ALL ma swoje limity, ale w dokumentacji nie są jasno sprecyzowane. Sądzę, że bezpiecznie będzie założyć iż iloczyn liczby kolumn docelowej tabeli oraz ilość klauzul INTO nie może przekraczać 65000.
Inną emulacją value constructor w Oracle przed 23c jest wykorzystanie Common Table Expressions.
INSERT INTO t (c) WITH p AS ( SELECT 1 FROM dual UNION ALL SELECT 2 FROM dual UNION ALL SELECT 3 FROM dual ) SELECT * FROM p;
Czyli dane do komendy INSERT przekazujesz przy pomocy klauzuli WITH i komendy SELECT.
Składnia powyższych dwóch metod nie jest tak elegancka, czytelna i przenaszalna jak value constructor, ale działa. Tutaj także oszczędzasz na komunikacji sieciowej i parsowaniu. W oby przypadkach trzeba mieć na uwadze, że wstawią się wszystkie rekordy lub żaden.
Weryfikacja
Pokazałem 4 metody optymalizacji wstawiania wielu rekordów do bazy danych.
’Wiele’ jest dość pojemnym określeniem. Bardziej precyzyjna definicja zależy od ilości rekordów oraz częstotliwości wykonywania procesu.
Wysiłek włożony w optymalizację powinna się opłacać. Skąd masz wiedzieć czy zastosowana metoda optymalizacji poprawia wydajność czy pogarsza?
Masz rację, czas wykonania jest ważny i dość prosty do zmierzenia. Ten czas, razem z ilością wstawionych danych, warto zapisywać do logu aby mieć perspektywę w sytuacjach awaryjnych. Zachęcam aby tym logiem była tabela w bazie danych.
Oprócz tego można zerknąć ile zasobów takich jak komunikacja z dyskami, parsowania zapytań czy transfer sieciowy zużyła sesja podczas wstawiania danych. W Oracle wszystko wyczytasz z wbudowanych widoków wydajnościowych. W PostgreSQL możesz bazować na wbudowanych statystykach lub doinstalować moduły jak auto_explain czy pg_stat_statements.
Warto wziąć także pod uwagę możliwość prostego restartu zakończonego niepowodzeniem procesu.
Podsumowanie
Motor bazy danych najwydajniej operuje na zbiorach danych. Nie inaczej jest z ich wstawianiem. Operacje INSERT zebrane w paczki wykonają się bardziej efektywnie niż wykonywane pojedynczo.
Zaprezentowałem 4 metody dla paczek o liczebności mierzonej co najwyżej w tysiącach rekordów. Daj znać, która jest najbardziej przydatna Tobie.
A co gdy do wstawienia masz setki milionów rekordów?
To bardzo dobre pytanie. Odpowiedzi na nie udzielę w następnym materiale o masowym ładowaniu danych.
Zapraszam na kolejne materiały. Wiesz co trzeba zrobić aby ich nie przegapić.
Epilog
Tę opcję zostawiłem na sam koniec jako bonus dla wytrwałych i ciekawych. Nie zachęcam do jej używania bo to proteza, a nie rozwiązanie.
Jeśli ładujesz dużo danych do Oracle, przy pomocy komend INSERT wypełnionych literałami, i nie możesz, nie chcesz lub nie umiesz tego zmienić to mam dla Ciebie poradę.
Jest w Oracle parametr, którym możesz wymusić na motorze aby mimo braku użycia zmiennych wiązanych nie parsował każdej komendy tylko wykorzystał już sparsowaną i podstawił do niej nowe dane.
Możesz to zrobić na poziomie sesji tuż przed serią insertów. Ten parameter to cursor_sharing i trzeba ustawić go na force.
alter session set cursor_sharing=force; INSERT INTO t VALUES ( 1 ); INSERT INTO t VALUES ( 2 ); INSERT INTO t VALUES ( 3 );
Niech moc będzie z Tobą.



