
Wstęp
W poprzednim materiale opisałem pierwszy przypadek z życia oraklowego debeowca. Zachęcałem do komentowania mojego podejścia i zaproponowania własnych pomysłów poprawiających wydajność SQL. Teraz zaprezentuję jak pomysły z komentarzy oraz moje wpłynęły na wydajność SQL.
Pomysły
W komentarzach pod materiałem znalazłem:
- Przepisanie tabeli w celu defragmentacji. Poniekąd coś takiego nastąpiło. Szerzej omówię za chwilę.
- Hint parallel może poprawić wydajność skanowania. O tym także szerzej za chwilę.
- Subpartycje są strzałem w dziesiątkę. Jak sądzisz według jakiego klucza należy je stworzyć?
Od siebie dokładam kompresję i usunięcie indeksu.
Analiza
Aby zapewnić optymalną wydajność aplikacji schemat bazy danych i pracujące na nim komendy SQL powinny ze sobą współgrać. W moim przykładzie zapytania filtrują dane według wartości kolumn data i źródło lub jedynie data.

Schemat tabeli poniekąd odpowiada części tych potrzeb. Z drugiej strony jest nieco nadmiarowy. Dane spartycjonowane są według wartości kolumny data.
CREATE TABLE t (
"data" DATE NOT NULL
,"źródło" VARCHAR2(20 CHAR) NOT NULL
[
Jakieś 20 innych kolumn
]
) PARTITION BY LIST ("data")
(
PARTITION "P20170101" VALUES (DATE'2017-01-01')
,PARTITION "P20170102" VALUES (DATE'2017-01-02')
[
Ponad 1500 innych partycji
]
)
W każdej partycji wartości kolumny data dla wszystkich rekordów są identyczne. Zapytania zawsze wybierają dane z jednego dnia. Plany wykonania zapytań wskazują, że optymalizator bierze to pod uwagę i ogranicza skanowanie do pojedyńczej partycji.

Warto zwrócić uwagę na kolumnę A-Time czyli faktyczny czas w którym zapytanie zostało wykonane. Wartość dla planu wykonania używającego indeksu jest wielokrotnie większa niż dla planu wykonania skanującego całą partycję.
Dlaczego? Czyż indeksy nie są remedium na każdą bolączkę wydajnościową?
Otóż nie.
Odczyt wszystkich danych z partycji, a z takim mam do czynienia, jest bardziej efektywny sekwencyjnie niż losowo przy użyciu indeksu. Motor bazy danych oprócz tabeli musi także odczytać indeks i robi to blok po bloku zamiast, jak w przypadku skanowania, wiele sąsiadujących bloków na raz.
Zauważ, że sam odczyt indeksu trwa prawie 2 minuty. W tym czasie odczytywane sa informacje o 27 milionach rekordów. Czyli odczytywana jest cała partycja indeksu aby wybrać z niej wskaźniki do 2219 rekordów. Nie uważasz, że to nie jest zbyt optymalne?
Wyjątkiem są zapytania filtrujące tak po dacie jak i po źródle. Niemniej rozkład wartości źródła dla poszczególnych partycji powoduje, że użycie indeksu nie zawsze byłoby opłacalne.
Wnioski
Indeks zbudowany na kolumnie data należy usunąć bo szkodzi. Najbardziej efektywną metodą dostępu do danych jest skanowanie całej partycji. Odczyta wszystkie bloki partycji, ale zrobi to po wiele na raz. Na dodatek nie przejdą przez cache, więc odpadnie narzut na zarządzanie pamięcią podręczną.
Jak można zoptymalizować sekwencyjny dostęp do danych?
Każdą z partycji można skompresować. Zajmie mniej bloków bazodanowych.
Gdyby była możliwość modyfikacji zapytań można by dopisać do nich hint parallel. Wtedy każda partycja mogłaby być skanowana kilkoma procesami.
Podział każdej partycji na subpartycje według wartości kolumny źródło dodatkowo ograniczy ilość czytanych danych i będzie niewrażliwe na ich nierównomierny rozkład.
O jakiej bardzo ważnej optymalizacji jeszcze nie wspomniałem?
Masz rację – warto porozmawiać z właścicielem danych czy na pewno ich wszystkich potrzebuje. Rozmiar tabeli oraz fakt, że przechowuje dane nawet sprzed ośmiu lat wskazują, że istnieje cień szansy, że zapomniano zaimplementować cykl życia danych. Warto także wziąć pod uwagę, że cykl życia danych może być wymuszony regulacjami.
Indeks
Usunięcie indeksu jest najłatwiejszą do przeprowadzenia optymalizacją. Niemniej życie uczy, że może być traktowane jak herezja przez zainteresowanych. Indeksy łatwo się dodaje bo wyraźnie widać potrzebę i, gdy są używane, zazwyczaj poprawę wydajności. Trudno się je usuwa bo nikt nie wie jak sprawdzić czy na pewno nie są używane.
Usunięcie indeksu trwa sekundy. Jest to operacja na słowniku bazy danych. W moim przypadku stabilizuje plan wykonania. Teraz nie ma innej ścieżki dostępu do danych jak pełny skan partycji.
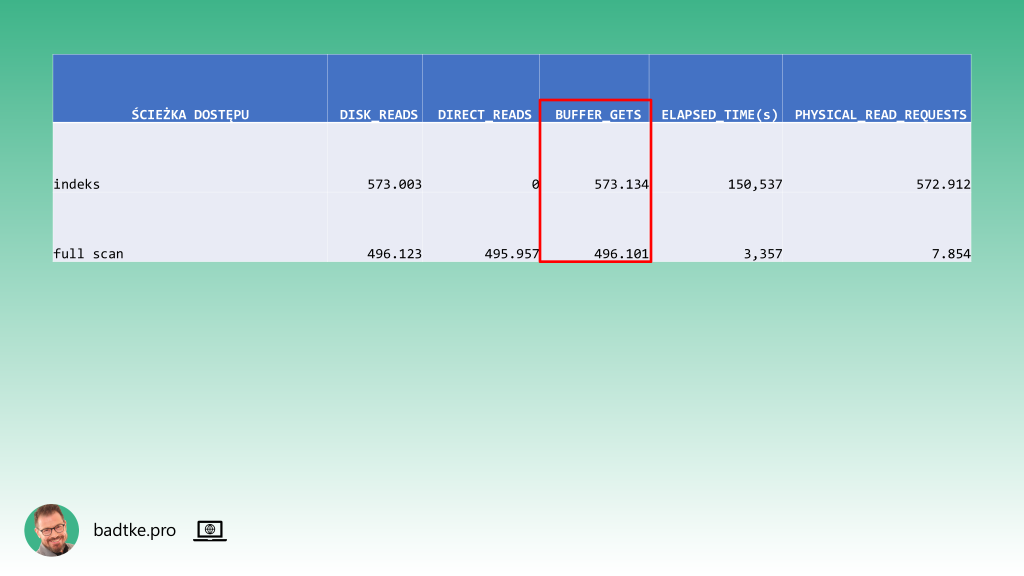
Skanując całą partycję instancja wykonuje mniej odczytów. Dodatkowo czyta szybciej bo ścieżką bezpośrednią.
Skoro optymalizator nie ma wyboru to aktualność statystyk jest drugorzędna. Aby niepotrzebnie nie zużywać zasobów instancji na naliczanie statystyki można kopiować ze starszych partycji do nowszych. Rozkład danych jest podobny.
Kompresja
Oracle dostarcza różnych możliwości kompresowania danych. Na niektóre trzeba mieć licencję Advanced Compression Option. Użyta przeze mnie nie wymaga osobnego licencjonowania. Jej ograniczeniem jest kompresowanie jedynie danych znajdujących się w tabeli. Nowe dane nie zostaną skompresowane. Nadaje się idealnie dla mojego przypadku. Nowe dane zapisywane są w najnowszej partycji i nigdy nie są modyfikowane.
Tworzę pętlę w PL/SQL kompresującą partycję po partycji poczynając od najnowszych. Operacja jest przezroczysta dla aplikacji.
declare
v_sqlstmt varchar(222);
begin
for i in (select partition_name from user_tab_partitions where table_name='T'
and compression!='ENABLED' order by partition_position desc)
loop
v_sqlstmt := 'alter table T move partition '||i.partition_name||' compress';
execute immediate v_sqlstmt;
end loop;
end;
/
Skompresowane partycje zajmują jedynie 40% poprzednio zajmowanej przestrzeni dyskowej. Dzięki temu zapytania wykonują się w około 20% krótszym czasie. Instancja wykonuje mniej IO aby odczytać partycję.
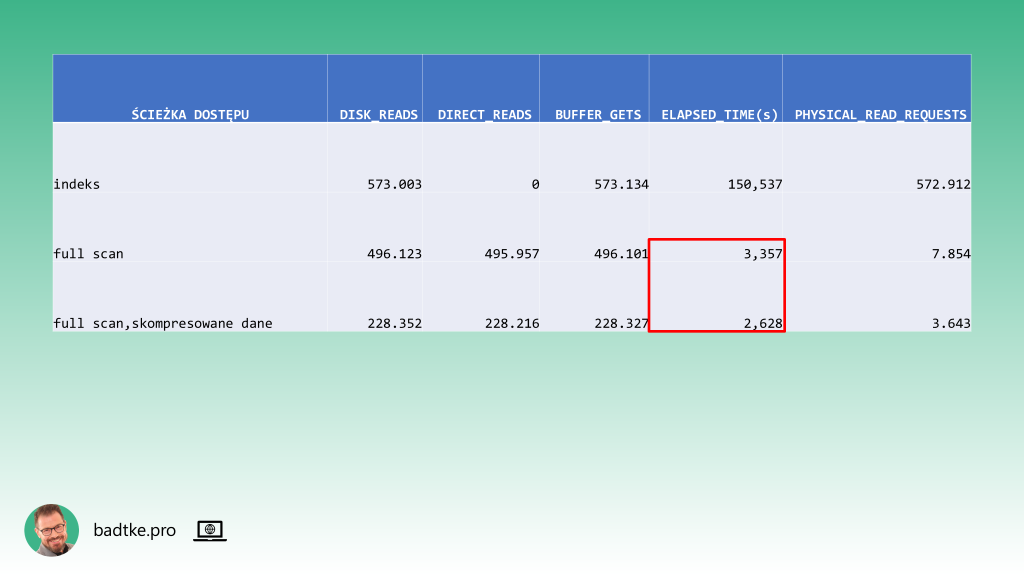
Oprócz tego tabela chudnie z 7TB do 3TB. Co ma wpływ na czas wykonania bekapu oraz czas jego odtworzenia. Nie wspominając o kosztach nośników w macierzach klasy enterprise. Należy jeszcze utworzyć job który codziennie skompresuje wypełnioną danymi partycję z dnia poprzedniego.
Subpartycje
Zasady dla których warto było partycjonować tabelę obowiązują także dla subpartycji. Zapytania filtrujące rekordy według wartości kolumn data i źródło zawsze wybierają wszystkie rekordy danej partycji mające określoną wartość w kolumnie źródło.
Indeks byłby przydatny dla wartości pojawiających się w niewielu rekordach natomiast nie byłby przydatny dla wartości pojawiającej się w znacznej liczbie rekordów. Wtedy i tak kończyłoby się skanowaniem całej partycji.
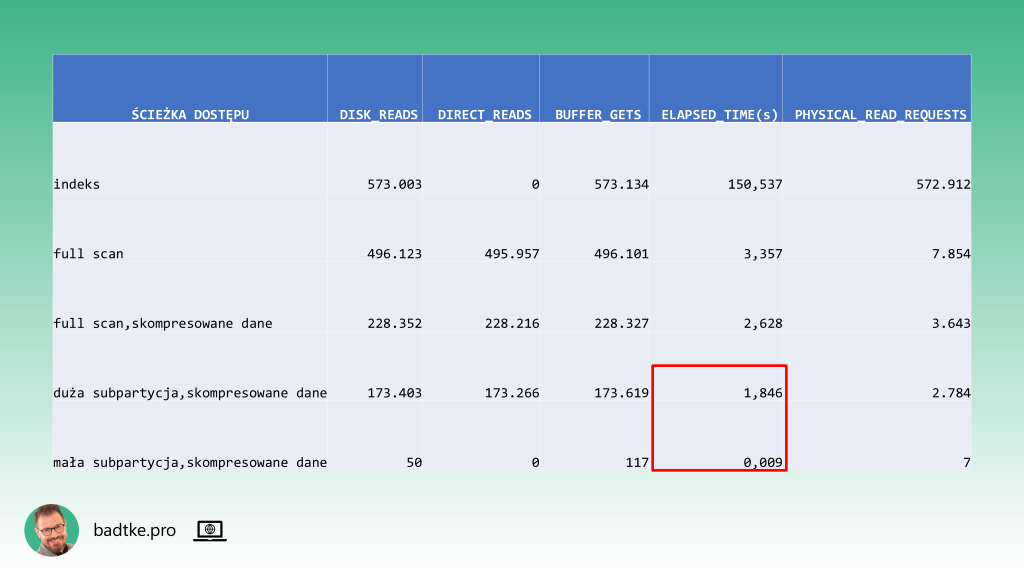
Subpartycje według listy wartości kolumny źródło rozwiązują ten problem. Optymalizator zawęzi skanowanie danych jedynie do subpartycji z pożądaną wartością w kolumnie źródło niezależnie od liczby znajdujących się w niej rekordów.

Dodanie subpartycji to zmiana schematu tabeli wiążąca się z przepisaniem danych do nowych segmentów. Od Oracle 12.2 może być wykonana jedną komendą bez przerywania dostępu do danych.
ALTER TABLE t MODIFY
PARTITION BY LIST ( "data" ) AUTOMATIC
SUBPARTITION BY LIST ( "źródło" )
SUBPARTITION TEMPLATE (
SUBPARTITION a VALUES ( 'A' ) COMPRESS
,SUBPARTITION b VALUES ( 'B' ) COMPRESS
,…
,SUBPARTITION p_default VALUES ( DEFAULT ) COMPRESS
)
(
PARTITION p20160101 VALUES ( date'2016-01-01' )
) ONLINE;
W wersjach wcześniejszych trzeba jawnie przepisać dane do nowej tabeli. Na przykład używając pakietu DBMS_REDEFINITION. Czas wykonania zapytania skraca się w zależności od wielkości konkretnej subpartycji.
Kasowanie danych
Właściciel danych potwierdził, że potrzebuje jedynie dane nie starsze niż trzy lata. Czyli z tabeli można usunąć pięcioletnią historię.
Należy także wdrożyć automatyczny job kasujący najstarszą partycję w momencie gdy przestaje być potrzebna. Do odzyskania jest ok 1TB przestrzeni dyskowej.
Podsumowanie
Dzięki zastosowaniu odpowiedniego partycjonowania i kompresji danych czas wykonania zapytania na całej partycji zmniejszył się z ponad dwóch minut do dwóch i pół sekundy.
Ograniczenie wybieranych danych do najliczniejszego źródła skutkuje czasem wykonania poniżej dwóch sekund.
Natomiast czas wykonania zapytania ograniczonego do najmniej licznego źródła to niespełna jedna milisekunda.
Zwróć uwagę, że tak ogromna poprawa wydajności została osiągnięta jedynie odpowiednią organizacją danych w bazie danych. Nadmiarowość w postaci indeksu mało, że nie została wykorzystana to wręcz została usunięta. Dzięki temu, niejako przy okazji, poprawiła się także wydajność ładowania danych do nowej partycji. Dane zostały w tych samych plikach bazodanowych na tych samych dyskach.
Zaowocowała znajomość danych, sposobu ich przetwarzania oraz funkcjonalności motoru.
Nic z tego nie byłoby możliwe gdyby nie współpraca administratora baz danych, dewelopera i właściciela danych.



