
Aby zdalnie i wydajnie obsługiwać żądania użytkownika instancja bazy danych potrzebuje 7 zasobów. Siódmy cię zaskoczy. Daj znać w komentarzu co o nim sądzisz.
CPU i RAM
Skoro instancja bazy danych jest zbiorem procesów i obszarów pamięci RAM to oczywistą oczywistością jest, że procesorów oraz pamięci RAM potrzebuje jak ryba wody. Niemniej procesor procesorowi nie jest równy. Szczególnie w środowisku zwirtualizowanym.
Klasycznie instancje bazy danych posadowione mogą być na urządzeniu, które obecnie nazywane jest bare metal. Czyli po prostu na komputerze z zainstalowanym systemem operacyjnym. W zależności od przewidywanego obciążenia instalowana jest określona ilość procesorów oraz pamięci RAM. Po co instancji RAM mówiłem w materiale o terminach bazodanowych.
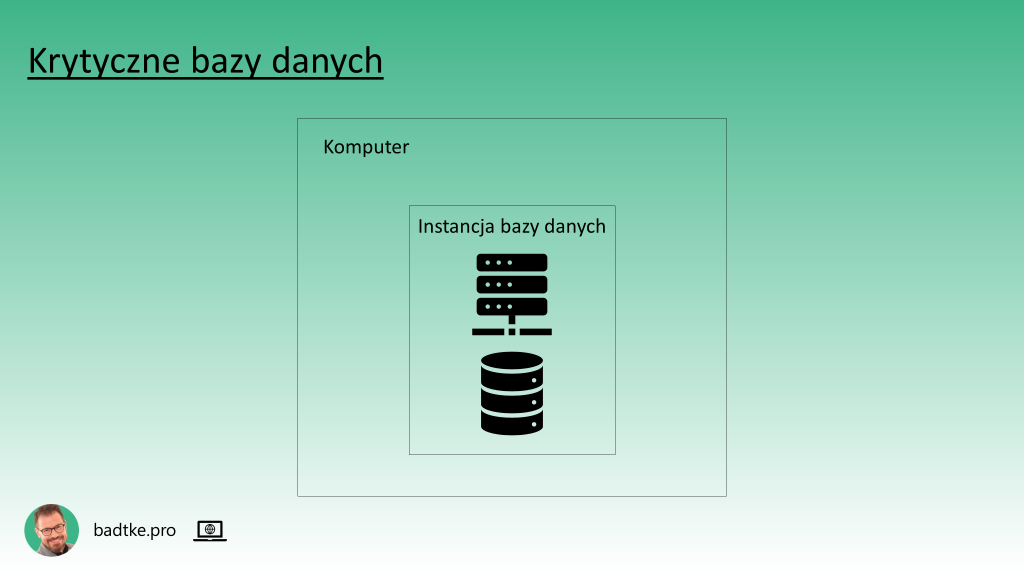
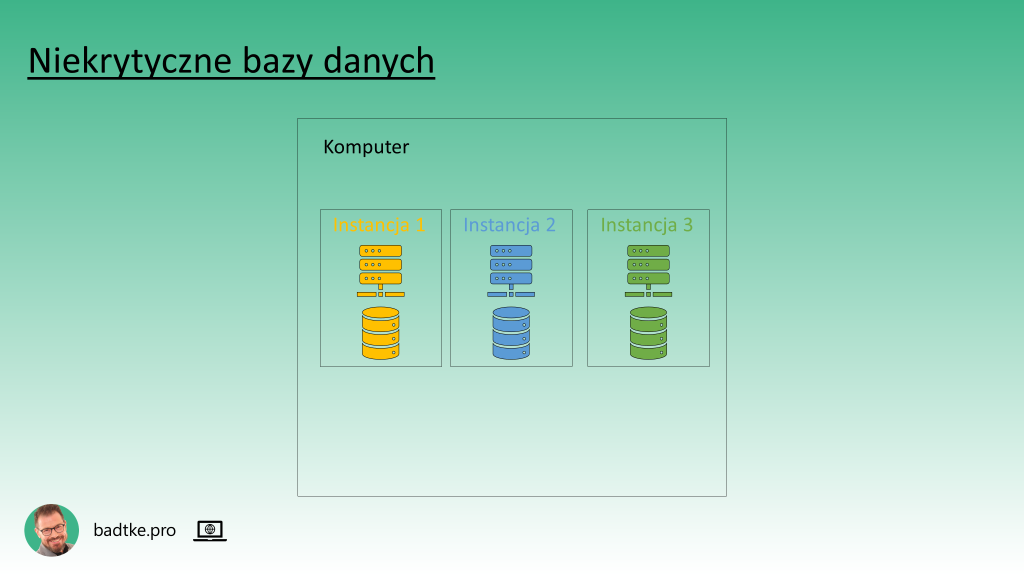
Instancje generujące duże obciążenie uruchamia się samotnie na dedykowanym komputerze. Zazwyczaj są to te krytyczne dla działania przedsiębiorstwa. Instancje o mniejszym apetycie na moc obliczeniową i mniej krytyczne zazwyczaj uruchamiane są po wiele na jednej maszynie. Systemem operacyjnym zazwyczaj jest jakaś wersja systemu UNIX lub Linux. Choć są odważni co wykorzystują Windows.
System operacyjny zarządza procesami instancji bazy danych, obszarami pamięci oraz dostępem do binariów motoru bazy danych i plików bazy danych. Dba o ich bezpieczeństwo oraz zapewnia dostępność zasobów komputera. Jak na przykład czas procesora czy karty sieciowe. Systemy UNIX i Linux dbają o to trochę lepiej niż Windows dlatego dominują w zastosowaniach.
Niedoszacowanie ilości procesorów czy RAM łatwo naprawić. Wystarczy dokupić kolejne procesory lub RAM. Trochę większym problemem jest gdy, na płycie głównej komputera, nie ma dość gniazd dla dodatkowych komponentów. Wtedy trzeba wymienić cały komputer.
Trudniejszą sytuacją jest gdy kupi się za dużo sprzętu. Wtedy, w raportach, widać, że obciążenie nie uzasadnia wydatków.
Łatwo, więc wyobrazić sobie sytuacje gdy dla jednego systemu kupiono za dużo, a dla drugiego za mało. Niefortunnie się składa gdy nie można fizycznie przełożyć komponentów z jednego komputera do drugiego.
Dygresja: podobno takie były początki Amazon Web Services. Kupili dużo sprzętu dla którego nie mieli zastosowania. Wtedy wpadli na pomysł aby udostępniać go, innym firmom, przez internet. Znasz szczegóły o początkach AWS to podziel się nimi w komentarzu.
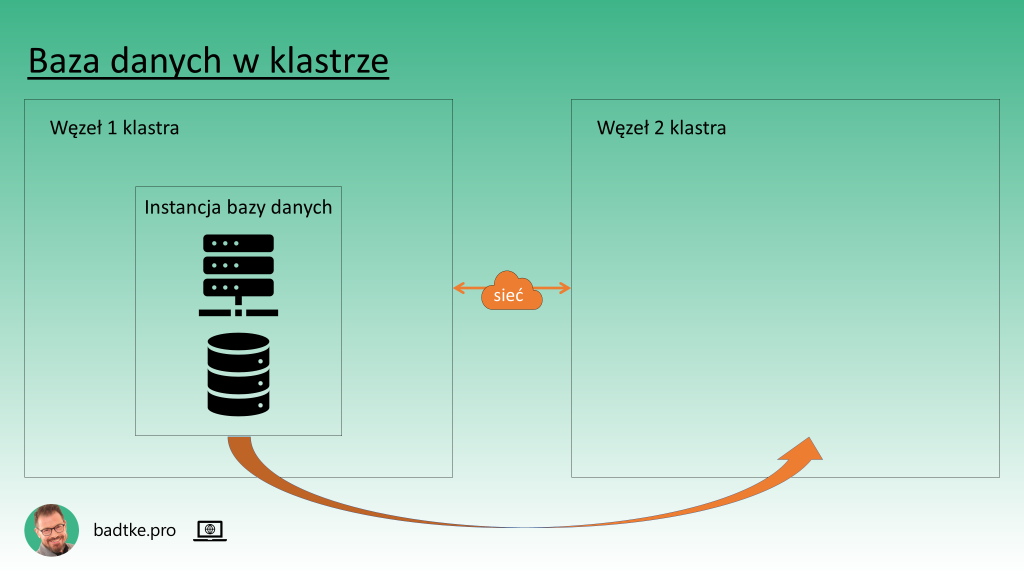
Każda wymiana fizycznego procesora czy pamięci RAM wymaga wyłączenia komputera. Konsekwencją czego jest niedostępność działającego na nim oprogramowania. Na przykład instancji bazy danych. Aby czas niedostępności skrócić można połączyć fizyczne komputery w klastry i wystartować instancję na innym komputerze klastra. Działa gdy komputery są podobne i zarządzane przez ten sam system operacyjny. No i gdy zakupiono, często kosztowne, oprogramowanie klastrowe.
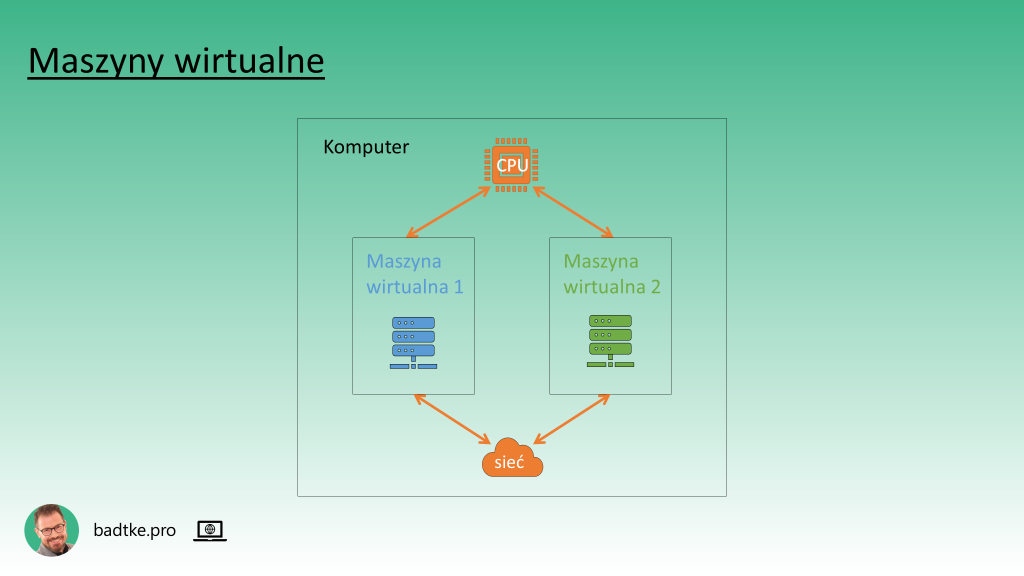
W sukurs przychodzi wirtualizacja. Czyli oprogramowanie udające inny komputer niż ten na którym jest uruchomione. Taki udawany komputer to maszyna wirtualna. Podczas tworzenia maszyny wirtualnej definiujesz ile wirtualnych procesorów oraz ile wirtualnego RAM ma mieć. Niektóre wersje oprogramowania wirtualizacyjnego umożliwiają sterowanie ilością procesorów oraz RAM bez restartu całej wirtualnej maszyny. W efekcie możliwe jest dokładniejsze zarządzanie pojemnością systemu. Czyli łatwiej możemy zadbać aby każda złotówka wydana na gigahertce procesora i gigabajty RAM znalazła swoje uzasadnienie.
Maszyna wirtualna jest zestawem plików na dysku. Można je przesłać na inny komputer z zainstalowanym oprogramowaniem wirtualizacyjnym i uruchomić. Może to być dowolny komputer z dowolnym systemem operacyjnym. Ważne aby wersja oprogramowania wirtualizacyjnego się zgadzała. Jak możesz się domyślać powstawanie i kasowanie maszyn wirtualnych jest znacznie szybsze niż zakup, instalacja i późniejsze złomowanie komputera fizycznego. Z punktu widzenia aplikacji, na przykład instancji bazy danych, to czy komputer jest fizyczny czy wirtualny jest przezroczyste.
Wszystkie maszyny wirtualne pracujące na jednym komputerze fizycznym współdzielą jego komponenty oraz oprogramowanie wirtualizacyjne, które pracuje pod kontrolą tego samego systemu operacyjnego. Rodzi to nowe wyzwania jeśli chodzi o dostęp i bezpieczeństwo. Trzeba pamiętać, że maszyny wirtualne są specyficzne dla danego oprogramowania wirtualizacyjnego. Obojętnie czy on-premises czy w chmurze. Niemniej dostawcy chmury udostępniają narzędzia konwertujące formaty maszyn wirtualnych. O ile ta maszyna wchodzi do ich chmury.
Niskie, w porównaniu do komputera fizycznego, koszty posiadania maszyny wirtualnej mogą być uzasadnieniem do stawiania dedykowanych, jednej instancji bazy danych, instalacji. Dzięki temu jakiekolwiek prace dotyczące tego jednego systemu można wykonać w większej izolacji. Każda instancja bazy danych działa na dedykowanej tylko jej maszynie wirtualnej. Dzięki temu konflikty pomiędzy różnymi instancjami baz danych działającymi na tym samym komputerze są minimalizowane. Na przykład rywalizowanie o czas procesora, niedostępność maszyny czy specyficzną wersja systemu operacyjnego.
Maszyna fizyczna czy wirtualna każda dysponuje i uruchamia swoją pełną wersję systemu operacyjnego. Po co każdej instancji bazy danych cały własny system operacyjny? Przecież jądro systemu i kluczowe biblioteki systemowe mogą być takie same. Tak prawdopodobnie myśleli twórcy konteneryzacji. Jest to inny niż maszyna wirtualna pomysł na wirtualizację środowiska pracy aplikacji.
Podstawowa różnica pomiędzy maszynami wirtualnymi, a kontenerami jest taka, że maszyny wirtualne wirtualizują sprzęt, a kontenery system operacyjny. Wirtualizują inne warstwy. Niemniej warto pamiętać, że przenoszenie maszyny wirtualnej pomiędzy platformami wirtualizacyjnymi – na przykład pomiędzy chmurami – jest znacznie trudniejsze niż przenoszenie kontenerów.
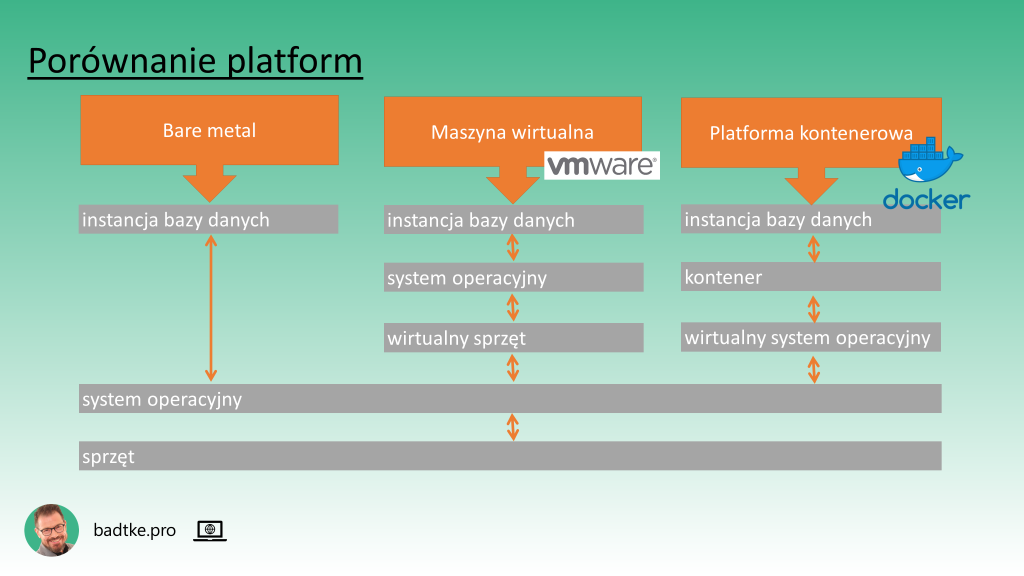
Instalacja instancji bazy danych w kontenerze jest możliwa choć może napotykać pewne trudności techniczne. W środowiskach produkcyjnych kompromisy mogą być niełatwe do zaakceptowania. Warto pamiętać, że baza danych i kontenery to produkty u podstaw których legły zupełnie przeciwstawne założenia. Podstawą instancji bazy danych jest dbanie o spójność i trwałość danych. Czyli zachowanie stanu danych. Podczas gdy kontenery z założenia są bytami efemerycznymi. Zostały zaprojektowane dla aplikacji, których stan nie musi być zachowany. Które można szybko i bez szkody dla świadczonej usługi wyłączyć i włączyć na zupełnie innej maszynie. Jeśli widzisz jakieś powody dla których warto żenić te przeciwstawne podejścia to daj znać w komentarzu. Parafrazując Władysława Bartoszewskiego: nie wszystko co sie opłaca warto.
Kontenery łatwo przenosić pomiędzy fizycznymi maszynami. Stworzenie i uruchomienie kontenera zabiera bardzo mało czasu. Wszystkie kontenery działające na jednym komputerze fizycznym współdzielą jego komponenty oraz system operacyjny. Zapewnienie bezpieczeństwa takiemu systemowi zwiększa poziom komplikacji. Trzeba pamiętać, że złamanie zabezpieczeń jednego kontenera naraża wszystkie inne działające na fizycznej maszynie.
Nośniki
Baza danych zapewnia trwałość danym. Z uwagi na korzystny stosunek pojemności do ceny optymalnym urządzeniem do realizacji tego celu jest dysk twardy. Oprócz trwałości zapewnia także szybki dostęp do losowych fragmentów danych. Tłumaczy to jego popularność.
Niemniej dysk twardy to urządzenie mechaniczne. Zawodne i mające fizyczne ograniczenia. Aby zminimalizować wpływ minusów na działanie bazy danych stosuje się technologię RAID. Trzeba mieć na uwadze, że instancja bazy danych obsługuje wiele żądań dostępu do danych jednocześnie. Im więcej żądań tym większa presja na system dyskowy. Z kolei dysk twardy ma skończoną i dość niewielką ilość głowic, którymi czyta i pisze dane. Głowice nie mogą być wszędzie w tym samym czasie. Rozwiązaniem tego problemu jest prezentacja wielu dysków fizycznych jako pojedynczych logicznych wolumenów.

Najbardziej popularnymi rozwiązaniami RAID są RAID1+0, inaczej nazywany RAID10. Oraz RAID5. Każdy ma swoje wady i zalety. Zazwyczaj RAID10 stosuje się dla krytycznych systemów produkcyjnych, a RAID5 dla wszystkich pozostałych. Cyfry po słowie RAID oznaczają sposób konfigurowania dysków twardych.
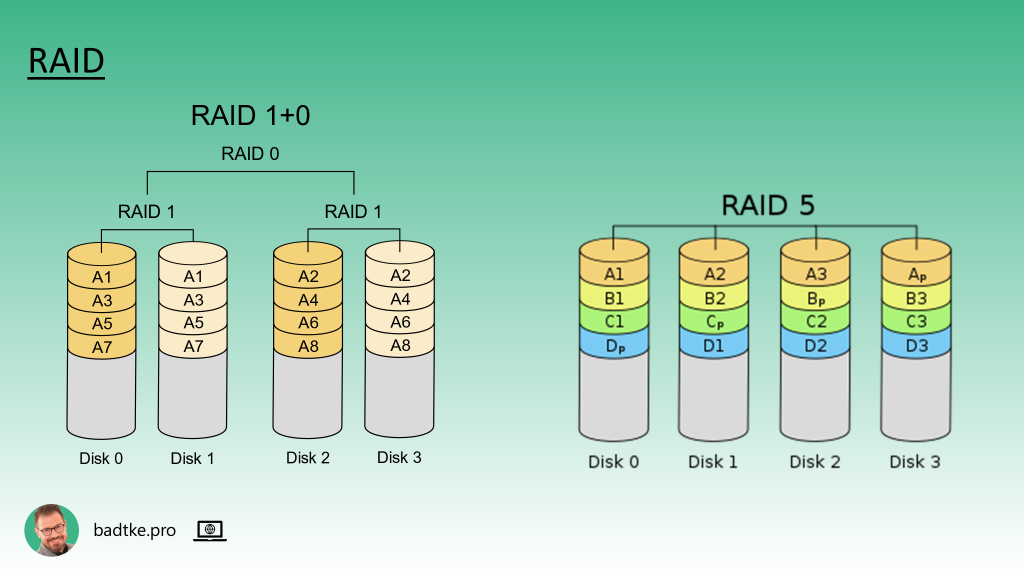
RAID10 zapewnia największą wydajność i największe bezpieczeństwo za cenę najwyższych kosztów. Jest zalecany przez niektórych producentów motorów baz danych. Czasem określany mianem SAME. Z angielskiego Stripe And Mirror Everything.
Jakkolwiek dyski nie byłyby skonfigurowane to zapisana na nich baza danych powinna być zaszyfrowana. Producenci motorów baz danych dostarczają odpowiednich narzędzi aby szyfrować dane podczas transferu pomiędzy pamięcią komputera, a dyskiem. Możesz spotkać się z określeniem szyfrowanie danych w spoczynku. Po angielsku encryption in rest. Dzięki temu wykradzenie plików bazy danych nie da natychmiastowego dostępu do danych. A jeśli zastanawiasz się jak to możliwe aby wykraść bazę danych to proponuję zmienić pytanie. Zamiast zastanawiać się jak, na kiedy to się stanie. Dlatego regulatorzy potrafią wymagać szyfrowania baz danych. Szyfrowanie bazy danych jest przezroczyste dla aplikacji klienckiej.
Jak wcześniej wspomniałem dyski twarde to zawodne urządzenia mechaniczne. Pomiędzy nimi, a instancją bazy danych jest mnóstwo innych urządzeń, złączek i kabelków. Każde z nich jest zawodne podobnie jak pamięć RAM komputera. Nie zawsze psuje się totalnie. Czasem raz działa, a raz nie działa. Dlatego warto skonfigurować instancję bazy danych aby sprawdzała sumę kontrolną bloku bazodanowego. Brzmi zbyt technicznie? Daj znać w komentarzu, a rozjaśnię.
Najpopularniejszym sposobem zabezpieczenia bazy danych jest zrobienie jej kopii zapasowej. Po angielsku backup. Czyli skopiowanie plików bazy danych na inny nośnik. Mogą to być inne fizyczne dyski twarde. Niemniej wciąż dużą popularnością cieszą się taśmy. Często udostępniane poprzez biblioteki taśmowe. Czyli wypakowane taśmami szafy wyposażone w robotyczne ramię przekładające taśmy pomiędzy półkami i napędami. Taśmy są tańsze, prostsze w obsłudze i bardziej odporne na wstrząsy niż dyski twarde. Najważniejsza różnica to sposób dostępu. Do danych na taśmie dostęp jest sekwencyjny.

Na jakikolwiek nośnik backup nie byłby robiony to powinien być zaszyfrowany. Nawet jeśli baza danych jest zaszyfrowana. Trzeba mieć na uwadze, że podczas wykonywania backupu dane z bazy danych często transferowane są siecią. Na przykład pomiędzy komputerami czy napędami dyskowymi lub taśmowymi. Szyfrowania backupu mogą wymagać regulatorzy.
Taśmy są znacznie tańsze niż dyski twarde. Niemniej nie są darmowe. Warto opracować politykę backup’ową pozwalającą na ich ponowne użycie. Polityka powinna być spójna z potrzebami przedsiębiorstwa i wymogami regulatora. Część producentów motorów baz danych dostarcza narzędzi do automatycznego zarządzania backup’ami. Ale to temat na osobny materiał.
Zakończone sukcesem ataki ransomware nie są nagłaśniane. Badania i zdrowy rozsądek podpowiadają, że atak ransomware może rozpocząć się od systemu backup’owgo. Są po temu dwa powody:
- Użytkownik wykonujący backup musi posiadać wysokie uprawnienia w bazie danych bo czyta wszystkie jej pliki. Zdobycie, więc jego hasła otwiera drzwi do danych.
- Drugim powodem jest, dostępność backupów. Firmy posiadające dostępne backupy są twardsze w negocjacjach okupu. Aby zmiękczyć stanowisko szantażowanej firmy trzeba usunąć jej backupy.
Proponuję sprawdzić czy w Twoim przedsiębiorstwie hasło na użytkownika backup’owego trzymane jest otwartym tekstem w pliku. Daj znać w komentarzu.
Warto pamiętać, że dobrym zabezpieczeniem jest trzymanie backupów w lokalizacji niedostępnej sieciowo. Czyli offline. Dostępne są systemu backupowe robiące to automatycznie. Dane krytyczne mające przetrwać lokalny kataklizm warto trzymać w odległej geograficznie strzeżonej lokalizacji. Czyli offsite. Skomentuj czy dla ciebie backup w chmurze jest wystarczająco offline, offsite i strzeżony.
Sieć
W materiale o architekturach mówiłem, że motor bazy danych ma architekturę klient-serwer. Klienci łączą się z instancją bazy danych poprzez sieć. Zazwyczaj jest to sieć TCP/IP do której należy także internet. Aby instancja bazy danych była osiągalna poprzez sieć musi posiadać swój adres nazywany także numerem IP oraz przyznany port na komputerze na którym pracuje. Do tego portu przypisuje się proces nasłuchu instancji. Przyjmuje on połączenia przychodzące od klientów.
Powiązanie adresu IP oraz numeru portu możesz wyobrazić sobie jako biurowiec. Numer IP jest adresem budynku, a numer portu to numer pokoju w biurowcu. W każdym pokoju realizowana jest inna usługa, ale tylko jedna. Na przykład w pokoju 80 jest usługa http, w 1521 Oracle, a 5432 PostgreSQL. Są to domyślne numery. Administrator może zdecydować o innej dyslokacji usług. Może przypisać je do innych portów.
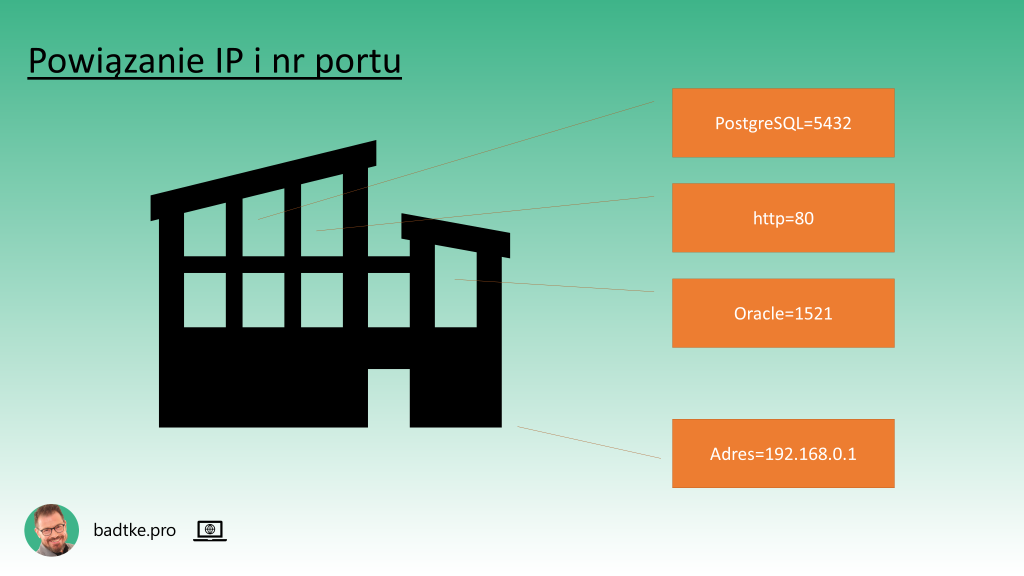
Kontynuując metaforę: po drodze do budynku przejeżdżasz przez wiele skrzyżowań i mostów. Niektóre ulice są jednokierunkowe, inne ślepe, jeszcze inne dwujezdniowe z barierkami pomiędzy jezdniami. W ten sposób możesz wyobrazić sobie ruch w sieci. W sieci ruchem sterują urządzenia nazywane routerami, switchami czy firewallami. Aby podłączyć się do instancji bazy danych urządzenia sieciowe muszą być skonfigurowane w taki sposób aby to podłączenie umożliwić. W bezpieczeństwie króluje zasada: co nie jest dozwolone jest zakazane. Czyli jeśli ruch do adresu IP i portu instancji bazy danych nie jest otwarty to aplikacja kliencka się nie podłączy.
Transmisja siecią komputerową odbywa się z wykorzystaniem tzw. Pakietów. Gdy pakiet znajdzie się w sieci to każdy kto ma dostęp do tego fragmentu sieci może ten pakiet podsłuchać. Ani pakiet, ani jego nadawca, ani jego odbiorca nie wiedzą, że został podsłuchany. Protokół którym aplikacja kliencka komunikuje się z instancją bazy danych jest prosty do odkrycia. W przypadku baz open-source jest wręcz jawny. Dlatego warto szyfrować komunikację aplikacji klienckiej z instancją bazy danych. Producenci motorów baz danych dostarczają odpowiednich narzędzi. Szyfrowanie jest przezroczyste dla aplikacji. Nazywane jest szyfrowaniem podczas transferu. Z angielskiego encryption in transit.
Mówiłem o szyfrowaniu danych na dysku i w sieci. Czy domyślasz się o jakim miejscu, gdzie dobrze jest szyfrować dane, nie wspomniałem? Daj znać w komentarzu.
Uprawnienia
Bezpieczeństwo danych składa się z warstw. Każda z warstw jest do pokonania. Jest to tylko kwestia czasu i determinacji włamywacza. Warstwą najbliżej danych są uprawnienia w bazie danych. Aby aplikacja kliencka mogła podłączyć się do instancji musi posiadać konto w bazie danych na które będzie się łączyć. Konto to musi mieć uprawnienia do nawiązywania połączeń. Niektóre motory bazy danych potrafią obsłużyć wiele baz danych jedną instancją. W takim przypadku konto musi mieć uprawnienia do korzystania z danej bazy danych. Czyli stać się jej użytkownikiem.
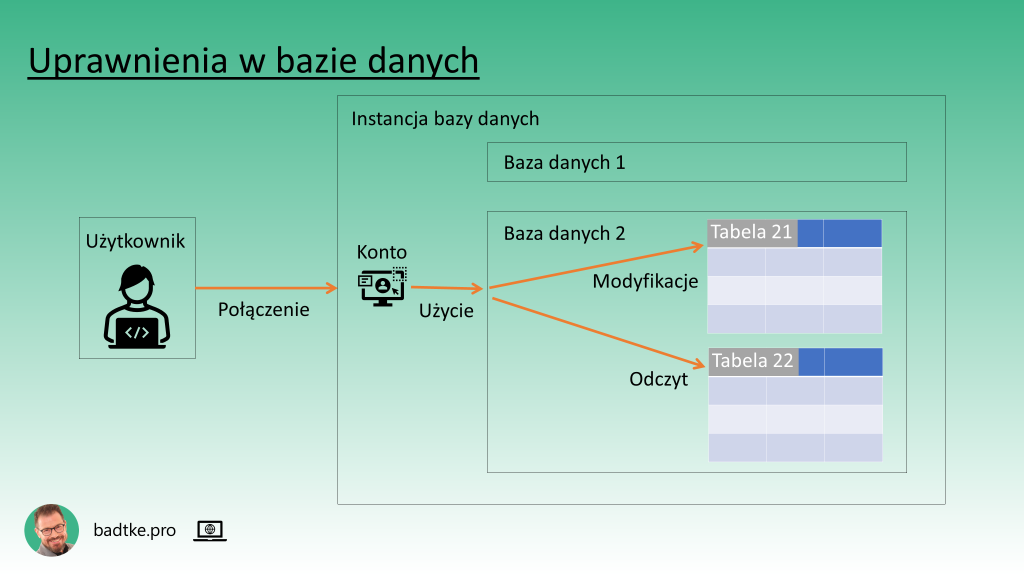
W obrębie bazy danych uprawnienia nadawane są do obiektów w których przechowywane są dane lub które manipulują danymi. Uprawnienia z grubsza można podzielić na uprawnienia do czytania i do modyfikacji. Różne motory baz danych stosują różną granulację uprawnień. Zazwyczaj jest to granulacja pionowa. Czyli jeśli użytkownik ma uprawnienia do modyfikacji określonych danych to może modyfikować je wszystkie. Niezależnie od przechowywanych wartości.
Jedynym motorem baz danych pozwalającym na granulację poziomą jest Oracle 23c. Dysponuje funkcjonalnością nazywaną SQL Firewall. Czyli uprawnienia bazodanowe dają ci dostęp do danych dotyczących sprzedaży firmy, ale SQL Firewall udostępni jedynie dane dotyczące sprzedaży w Bydgoszczy.
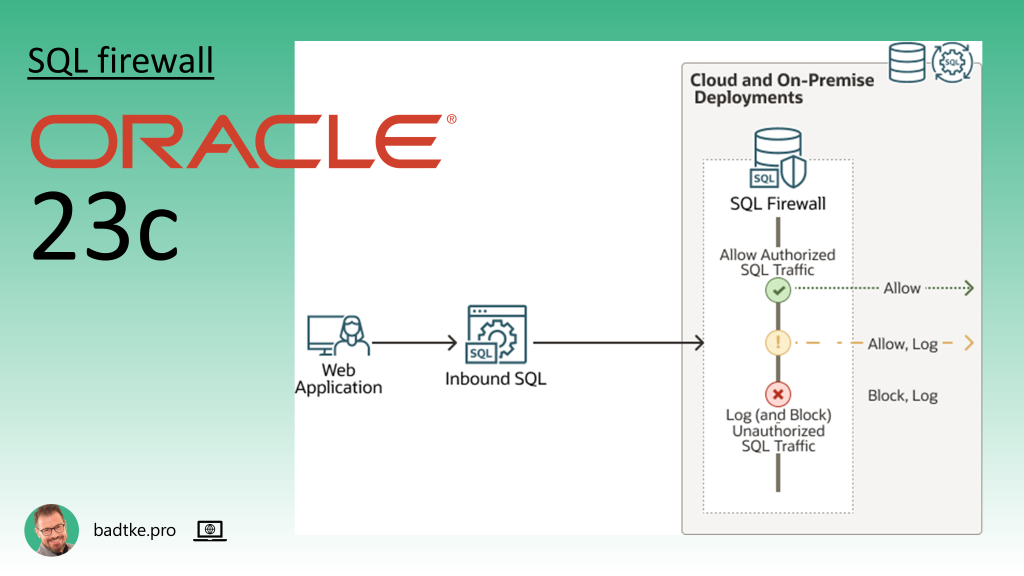
Szczegółowe zarządzanie uprawnieniami w bazie danych może wydawać się uciążliwe. Aby ułatwić sobie pracę wystarczy nadać aplikacji bardzo szerokie uprawnienia. Jako administrator baz danych nie raz widziałem takie prośby. Jest to bardzo groźne. Aplikacja korzystająca z bazy danych musi mieć dozwolone przejście przez wszystkie warstwy zabezpieczeń przedsiębiorstwa. Jedyną ochroną danych są zabezpieczenia w bazie danych. Gdy te będą nadawane zbyt hojnie włamywacz będzie miał rozległy dostęp. A trzeba pamiętać, że aplikacja kliencka jest najsłabszym ogniwem w systemie zabezpieczeń. Nabiera coraz większego znaczenia w dobie wykorzystywania chat botów do generowania i debugowania kodu.
Oprócz nadawania użytkownikowi, na którym pracuje w bazie danych aplikacja kliencka, nadmiarowych uprawnień innym 'ułatwieniem’ jest wynoszenie zarządzania kontami użytkowników z bazy danych do aplikacji klienckiej. W takim przypadku aplikacja kliencka maskuje rzeczywistego użytkownika. Każde podłączenie do bazy danych identyfikowane jest jako aplikacyjne. W związku z tym nie można wykorzystać bazodanowych mechanizmów zabezpieczających dane przed niepowołanym dostępem i uszkodzeniem. Wg mnie, taki projekt aplikacji, wynika jedynie z nieznajomości mechanizmów bazodanowych oraz z nieumiejętności ich wykorzystania przez twórców aplikacji.
Rozwiązaniem pozwalającym śledzić kto jakie operacje na bazie danych wykonał jest audyt. Dostępny od dawna w wielu motorach baz danych. Rejestruje akcje użytkownika zamiast je ograniczać. Rejestr może być przeglądany. Gdy podejrzana akcja zostanie zauważona można podjąć kontrakcję. Na przykład administrator baz danych ma bardzo szerokie uprawnienia w bazie danych. Niemniej niekoniecznie powinien czytać ani modyfikować same dane. Można audytować takie akcje i prosić administratorów o wyjaśnienia dlaczego wykonali te niedozwolone. Audyt może także posłużyć jako źródło informacji o włamaniu. Jest spora szansa, że włamywacz nie będzie przestrzegał reguł przedsiębiorstwa w dostępie do danych. Prawdopodobnie będzie starał się odczytać znaczną ilość danych lub zmodyfikować kluczowe. Trzeba pamiętać, że taką informację posiądziesz się po fakcie. Wtedy może posłużyć do analizy post factum do jakich danych włamywacz uzyskał dostęp i co z nimi zrobił. Oraz gdzie sa luki w systemie zabezpieczeń.
Jak sądzisz czy administrator baz danych może modyfikować log audytu? Daj znać w komentarzu.
Czasem pojawia się pokusa aby swoją pracę zabrać do domu. Wystarczy przetransferować pliki maszyny wirtualnej, kontenera z bazą danych czy kopię bazy na swój domowy komputer i uruchomić. Trzeba pamiętać, że komputer domowy jest bardzo słabo chroniony przed atakami. Szczególnie jeśli pracuje pod kontrolą systemu Windows. Wg mnie transferowanie do domu bazy danych zawierającej prawdziwe dane przedsiębiorstwa jest karygodne. A nawet jeśli baza danych zawiera minimalna ilość zanonimizowanych danych to jej struktura oraz sposób działania aplikacji są prawdziwe. Potencjalny włamywacz może wykorzystać tę wiedzę aby dokonać włamu do przedsiębiorstwa. Podobnie groźne jest łączenie się przez internet do bazy danych przedsiębiorstwa nieszyfrowanym połączeniem.
Monitorowanie
Skuteczność zabezpieczeń jest wprost proporcjonalna do jakości monitoringu. Na przykład wspomniany wcześniej audyt przyniesie korzyści jedynie wtedy gdy jego logi będą regularnie analizowane. Każde naruszenie polityk będzie wywoływało z góry określoną akcję, a użytkownicy będą łatwi do identyfikacji. Łatwo będzie zmapować użytkownika w bazie danych na osobę używającą aplikacji klienckiej. Czasem używanie audytu wymuszane jest przez regulatorów.
Monitoring bazy danych jest procesem obserwacji i analizy wydajności, dostępności i bezpieczeństwa całego systemu bazy danych. Nie tylko instancji. Najlepszym bo najbardziej zaangażowanym systemem monitorującym są użytkownicy danych. Niemniej część firm o przekroczeniu limitów woli wiedzieć zanim dowiedzą się o tym tzw. użytkownicy końcowi. Takie firmy stosują systemy monitorujące dostarczane przez producentów motorów baz danych lub firmy trzecie. Na przykład Oracle Enterprise Manager, Zabbix czy SolarWinds. Daj znać jaki stosowany jest w Twojej firmie.
Wspomniane wcześniej limity inaczej nazywane są z angielska KPI – Key Performance Indicator. Dzięki nim wszyscy zainteresowani wiedzą kiedy system bazy danych działa dobrze, a kiedy niezadowalająco. O niezadowalających wskazaniach system informuje w zdefiniowany wcześniej sposób. Na przykład mejlem. Dzięki optymalnej konfiguracji odpowiednie osoby informowane są o zbliżającym się stanie krytycznym z wyprzedzeniem pozwalającym na podjęcie kontrakcji.
Warto monitorować, i zazwyczaj tak się robi, wszystkie elementy ekosystemu bazy danych. Począwszy od bazy danych na połączeniu klienckim kończąc. Monitoring pozwala także na wgląd w dane historyczne. Czasem zobaczenie bieżących danych na tle historycznych więcej mówi o aktualnym stanie niż suche liczby. Skutkiem ubocznym magazynowania danych wydajnościowych jest możliwość użycia ich do planowania pojemności całego ekosystemu, generowania raportów o stanie czy zarządzania alokacją zasobów dla poszczególnych komponentów.
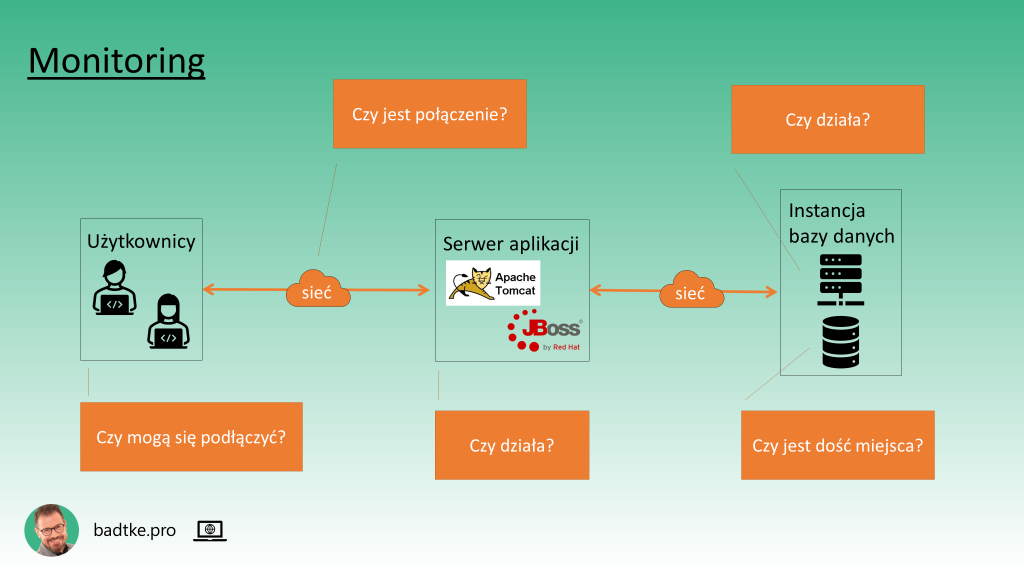
Jak pokazałem wcześniej dostępność bazy danych zależy od wielu składowych ekosystemu. Na przykład dysków i sieci. Niemniej, z punktu widzenia użytkownika, każda awaria komponentu pośredniego skutkuje niedostępnością danych. Dlatego najpopularniejszą awarią jest 'baza danych nie działa’.
Związany z monitoringiem jest skrót SLA. Czyli Service Level Agreement. Jest to umowa określająca warunki na jakich usługa jest świadczona przez dostawcę. Na przykład jakimi wartościami określana jest dostępność, wydajność czy bezpieczeństwo bazy danych. Za niedotrzymanie warunków umowy przewidziane są kary.
Larry Ellison, współzałożyciel Oracle, twierdzi, że automatycznie zarządzane bazy danych nie będą potrzebować ludzi. Będą administrować się same. Cóż, póki co, albo bazy nie są jeszcze aż tak automatyczne, albo nie potrafimy ich automatyzmu w pełni wykorzystać. Tak czy inaczej administrator baz danych dalej jest kluczowym zasobem ludzkim w IT.
Ludzie
System bazy danych spina wszystkie wcześniej wspomniane zasoby techniczne w sprawnie działającą całość. Jej głównym celem jest umożliwienie wydajnego dostępu do danych. Każdy zasób techniczny wymaga, od czasu do czasu, mniejszej lub większej interwencji ludzkiej. Spinającą rolę wśród zasobów ludzkich odgrywa administrator baz danych. Osoba pracująca na tym stanowisku kooperuje z innymi specjalistami zarządzającymi swoimi częściami infrastruktury informatycznej przedsiębiorstwa aby wydajny dostęp do danych zapewnić. Więcej o zadaniach administratora baz danych będzie w kolejnym materiale.
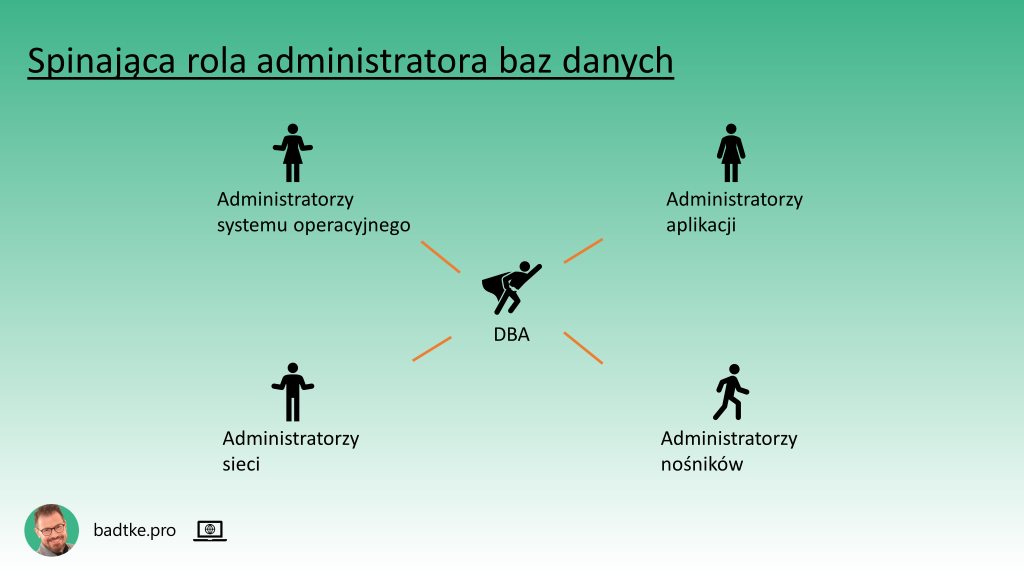
Ważną rolę, w procesie zapewniania wydajnego dostępu do danych, odgrywa tzw. Pierwsza linia wsparcia. Innymi określeniami ludzi pełniących tę rolę są: operatorzy czy pierwszy poziom wsparcia. Są oni punktem kontaktowym dla użytkowników, interesariuszy oraz administratorów. Odbierają komunikaty systemu monitorującego, o którym mówiłem wcześniej. Informacje o przekroczeniu stanów alarmowych przekazują odpowiednim administratorom. Od administratorów odbierają informacje o przywróceniu dostępu do danych i przekazują osobom korzystającym z danych. Osoby zatrudnione w pierwszej linii wsparcia zazwyczaj pracują w trybie zmianowym 24 godziny na dobę.
W przypadku niosących większe konsekwencje awarii systemu informatycznego przekazują informacje o postępie prac wzdłuż drabiny eskalacji. Na przykład od zaangażowanych w naprawę administratorów do przełożonych administratorów czy dyrekcji IT.
Pierwsza linia wsparcia może być zaopatrzona w procedury pozwalające na wykonanie dodatkowych, rutynowych sprawdzeń lub napraw dla najczęstszych zgłoszeń. Na przykład zmiana hasła dla konta. Niemniej najważniejszym zadaniem pracowników pierwszego poziomu wsparcia jest zapewnienie, że odpowiednie osoby zaangażowały się w rozwiązanie zgłoszenia użytkownika. Im większe kompetencje reprezentowane są przez pierwszą linię tym mniej obciążeni są administratorzy i tym większa jest dostępność danych.
Procedury
Zasób, który teraz wymienię, dla części może być ciężarem. Są to procedury. Mam świadomość, że nie po to człowiek zajmuje się informatyką aby pisać wypracowania. Jeśli sądzisz inaczej to daj znać w komentarzu.
Procedury wszyscy mamy w głowach. Są częścią naszej codzienności. Niemniej można wyobrazić sobie sytuacje gdy dobrze byłoby mieć je na umownym papierze. Mam na myśli sytuacje stresowe. Na przykład awarię głównej bazy danych. Konieczność jej odtwarzania z backup’u. Inną sytuacją mogą być powtarzalne zadania. Na przykład kolejna instalacja nowej wersji binarek motoru bazy danych. Jeśli Ciebie nigdy nie zgubiła rutyna koniecznie pochwal się tym w komentarzu. Dla mnie jesteś jednorożcem.

Na to nakłada się rotacja pracowników. Nowozatrudnieni potrzebują jasnych wytycznych jak postępować.
Każda procedura jest tylko tak dobra jak jest uaktualniona do bieżącej konfiguracji środowiska, dostępna oraz przetestowana. Chyba nie pomylę się za bardzo zakładając, że większość z nas jest przekonana co do potrzeby wykonywania backup’u. Ale kto regularnie testuje jego jakość? Na przykład odtwarzając na środowisku testowym.
Posiadanie aktualnych procedur znacznie eliminuje szanse na ludzki błąd. Dużo łatwiej jest kopiować gotowe, przygotowane na zimno i przetestowane komendy zamiast przypominać je sobie gdy są potrzebne. Na przykład jak postępować w przypadku odkrycia włamu do bazy danych?
Częścią procedur są polityki postępowania. Na przykład jak często i na jakich zasadach instalowane są poprawki i nowe wersje binarek motoru bazy danych? Czy takie działanie inicjowane jest przez właściciela danych czy przez administratorów bazy danych? W jakim czasie od wypuszczenia nowej wersji musimy uaktualnić używaną? Jak wnikliwie testować nową wersję? Jak postępować w przypadku nieudanego uaktualnienia? Jak postępować gdy aplikacja nie działa dość wydajnie na nowej wersji? Część wymagań narzucana jest przez audyt i regulatorów.
Podsumowanie
Do realizacji swoich funkcji wydajnego i bezpiecznego manipulowania danymi instancja bazy danych potrzebuje:
- Procesorów oraz pamięci RAM jako zasobów komputera fizycznego lub wirtualnego. Im mniej wirtualizacji tym większy wpływ na alokację zasobów i bezpieczeństwo.
- Nośnika danych. Dyski do dostępu natychmiastowego i taśmy do przechowywania kopii zapasowych. Oba zaszyfrowane
- Konfiguracji komponentów sieciowych umożliwiających komunikację aplikacji klienckiej z adresem IP i numerem portu instancji bazy danych
- Przemyślanych i spójnych uprawnień dostępu do danych
- Monitorowania dostępności, wydajności i bezpieczeństwa
- Administratorów zarządzających infrastrukturą oraz operatorów wspierających użytkowników danych
- Procedur obejmujących sposoby postępowania w przypadkach rutynowych jak i awariach
Jaki zasób dodasz do mojej listy?
To trzecia część cyklu o ekosystemie bazy danych.
Poprzednia: 5 architektur baz danych.
Kolejna część cyklu dotyczy 9 bazodanowych VIPów.



