
UTF-8 na dobre rozgościł się w bazach danych. Po co, więc typy znakowe NVARCHAR i NCHAR? Z których tylko NVARCHAR zasługuje na uwagę. Dotyczy także NVARCHAR2 w Oracle.
W najprostszych słowach typ NVARCHAR, i jego utuczony kuzyn NCHAR, służą do tego aby pomieścić wszystkie te znaki, które nie mieszczą się w VARCHAR. Nie mieszczą się z uwagi na ograniczenia domyślnego zestawu znaków bazy danych.
Dlaczego, więc nie ustawić bazy danych na UTF-32 i mieć możliwość przechowywania wszystkich znaków w VARCHAR? Nawet marsjańskiego alfabetu. Przeczytaj cały artykuł aby się dowiedzieć.
Kodowanie jednobajtowe
Obiegowa opinia głosi, że w typie VARCHAR przechowywane są znaki ASCII kodowane na jednym bajcie, a w NVARCHAR znaki w formacie Unicode kodowane na dwóch bajtach.
Dzięki temu łatwo policzyć ile znaków zmieści się w kolumnie i ile bajtów znajdzie się na dysku. Prawda?
Nie do końca.
O tym jaki zestaw znaków będzie domyślnie wspierany przez bazę danych decydujesz tworząc bazę danych. Domyślny znaczy obowiązujący w typach CHAR i VARCHAR.
Jeśli zdecydujesz się na zestaw znaków z rodziny Latin lub ISO 8859 wtedy znaki w obrębie serwera będą kodowane z użyciem jednego bajtu. Dzięki temu liczba podana jako rozmiar kolumny VARCHAR oznacza zarówno bajty jak i znaki.
W takim przypadku będziesz potrzebować, w swojej bazie danych, kolumn NVARCHAR aby zmieścić w nich znaki, których nie ma w domyślnym zestawie znaków bazy danych.
Jest to zrozumiałe. Na jednym bajcie można zakodować do 255 różnych wartości. To za mało aby oznaczyć litery wszystkich alfabetów na Ziemi.
Dla przykładu: gdy domyślnym zestawem znaków Twojego serwera baz danych jest obsługujący standard ISO 8859-1 czyli kraje Europy Zachodniej. To w kolumny typu CHAR i VARCHAR nie wstawisz znaków diakrytycznych polskiego alfabetu.
Żeby być dokładnym: wstawisz, bo to tylko bajtowy kod znaku, ale dla bazy danych będą oznaczać zupełnie co innego niż w języku polskim. Baza danych nie potraktuje ich jak polskich znaków diakrytycznych tylko jak znaki o identycznym kodzie, ale pochodzące z jakiegoś alfabetu Europy Zachodniej.
Na przykład: wstawiając do bazy danych z kodowaniem ISO 8859-1 polską literę 'Ą’. W bazie znajdzie się kod 161. Będzie on traktowany jak odwrócony wykrzyknik znany z hiszpańskiego.
Jeśli, więc chcesz aby Twoja baza danych potrafiła przechować i obsłużyć zarówno litery alfabetów Europy Zachodniej jak i polskie znaki diakrytyczne to potrzebujesz kolumn NVARCHAR. Ich zawartość kodowana jest zawsze w standardzie Unicode.
UWAGA: PostgreSQL nie posiada typu NVARCHAR.
NVARCHAR = Unicode
Standard Unicode nie gwarantuje kodowania na dwóch bajtach.
Znaki z zakresu 0-127 – czyli ASCII – kodowane są jednym bajtem w UTF-8. Powyżej, czyli 128-2047, są znaki polskie, cyrylica, hebrajskie czy arabskie. One kodowane są na dwóch bajtach. Większość znaków hinduskich, chińskich czy japońskich kodowana jest na trzech bajtach w zakresie 2048-65535. Znaki najwyższych zakresów 65536-262143 i 262144-1114111 kodowane są na czterech bajtach.
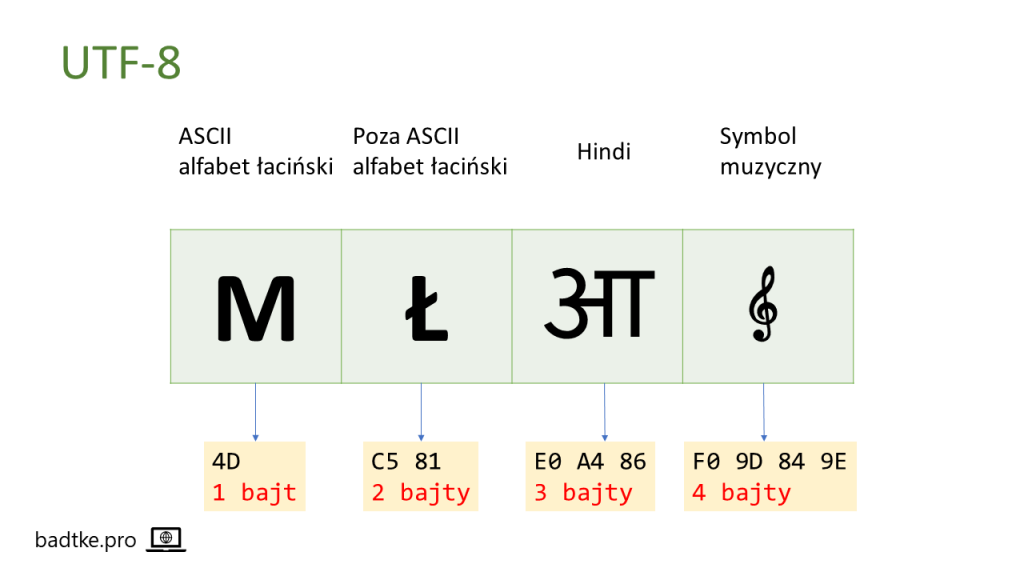
UTF-8 jest bardzo popularny. Dlaczego? Bo jest świetnym zestawem dla baz danych przechowujących głównie znaki ASCII. Znaki ASCII dalej zajmują tylko jeden bajt. Jedynie narodowe i specjalne od 2-4. Jeśli jest ich niewiele to zysk jest zauważalny.
Oprócz UTF-8, konsorcjum Unicode, zdefiniowało inne standardy. Na przykład UFT-16. Również dostępny w wielu motorach baz danych. W tym standardzie znaki z zakresu 0-65535 kodowane są na dwóch bajtach. A z zakresu powyżej 65535 na czterech.
Za to w UTF-32 wszystkie znaki zajmują 4 bajty.
Jak widzisz ilość przestrzeni dyskowej, którą zajmą Twoje łańcuchy znaków zależy nie tylko od typu wybranego dla kolumny. Zależy także od zestawu znaków wybranego dla bazy danych oraz z jakiego alfabetu pochodzić będą znaki.
Czyli decydując się na kodowanie znaków narodowych z wykorzystaniem UTF-8 w Twojej bazie danych, łańcuch znaków wstawiony do kolumny typu NVARCHAR(10) zajmie od 10 do 40 bajtów. W zależności od wstawionych znaków.
Wsteczna kompatybilność.
Zestaw znaków dla bazy danych wybierasz w momencie jej kreacji. Później nie jest łatwo go zmienić.
W czasach poprzedzających Unicode, jeśli Twoja aplikacja powstała z myślą o rynku polskim to wystarczył jej zestaw znaków ISO 8859-2. Mieści wszystkie potrzebne Polakom znaki.
Gdy aplikacja rozrosła się o rynki wschodnioeuropejskie trzeba było ją dostosować. Nie można zmienić zestawu znaków dla bazy danych, ale można dołożyć, czy skonwertować, część kolumn. Dzięki temu umożliwić przechowywanie w nich cyrylicy.
Od czasu opracowania UTF-8 wydaje się rozsądnym kompromisem. Znaki ASCII kodowane są na jednym bajcie. Polskie i inne europejskie narodowe znaki na dwóch. Azjatyckie na trzech. Specjalne na czterech. To niewielki narzut.
Trzeba pamiętać, że większość wiodących dostawców oprogramowania pochodzi z USA. Tam zestaw ASCII wystarczał.
Część baz danych dziedziczyła zestaw znaków po systemie operacyjnym. Gdy ten korzystał z ASCII baza danych, również tak była skonfigurowana.
UTF-8 pozwala na zachowanie wstecznej kompatybilności z ASCII. Konwersja nie przyniesie zaskoczeń w postaci dwukrotnego wzrostu zajętej przez znaki przestrzeni. Nie zmienią się także kody znaków. Nie trzeba dużych zmian w starej aplikacji aby dostosować ją do UTF-8.
Z drugiej strony UTF-8 jest na tyle pojemny, że pomieści wszystkie znaki narodowe. Dzięki temu nowsze wersje starej aplikacji, albo nowe aplikacje korzystające ze starej bazy danych będą mogły korzystać z dobrodziejstwa pojemności tego standardu.
Składowanie
Różne sposoby kodowania znaków standardu Unicode mają na celu optymalizację zużycia przestrzeni dyskowej. Jak również minimalizację narzutu na transfer sieciowy.
Dla języka Java standardem jest UTF-8. Podobnie jak dla HTML, XML i JSON. Pozwala to wygodnie pomieścić znaki narodowe i specjalne. Nie zużywając jednocześnie zbyt wiele dodatkowych bajtów na składowanie i transfer.
Elastyczność w składowaniu kodowania UTF-8 nie przychodzi za darmo. Aplikacja, jakakolwiek by nie była, musi obliczyć ile bajtów zajmuje znak. Nie ma jednoznacznego przełożenia jak w ASCII czy UTF-32. A to kosztuje CPU.
Zmienny rozmiar znaku w bajtach powoduje różne zapotrzebowanie na struktury pamięci. Dlatego, aby uprościć operacje na łańcuchach znaków UTF, w RAM konwertuje się je do UTF-32. Dzięki temu operacje jak obliczanie długości łańcucha czy wycinanie jego fragmentów jest bardzo proste i wydajne.
Warto mieć na uwadze, że UTF-8 koduje znaki z przedziału 2048-65535 na trzech bajtach. Podczas gdy UTF-16 znaki z tego samego przedziału tylko na dwóch bajtach. Jeśli zamierzasz składować dużo znaków z powyższego przedziału warto zastanowić się nad UFT-16 zamiast UTF-8.
Podsumowanie
Typ NVARCHAR miał na celu mieścić znaki narodowe nie mieszczące się w VARCHAR. Ze względu na domyślny zestaw znaków bazy danych.
Obecnie standard UTF-8 jest rozprzestrzeniony wśród języków programowania, systemów operacyjnych i dokumentów. Nie ma wyraźnego powodu aby nie wybierać go jako domyślnego dla bazy danych czy całego serwera baz danych. Tym sposobem typ VARCHAR pomieści wszystkie znaki.
O przewagach VARCHAR nad CHAR przeczytasz w moim artykule: CHAR, a VARCHAR – 2 mity, a rzeczywistość
Prowadzę szkolenia i kursy z podstaw SQL. Sprawdź ofertę moich kursów SQL.



