
99% problemów wydajnościowych komend SQL można rozwiązać pomagając optymalizatorowi wybrać właściwą driving table. Niniejszy artykuł jest wstępem do prezentacji metody jak to zrobić.
Wstęp
Co roku na rynek pracy wchodzi nowe żyjące najnowszymi technologiami gorącogłowe i gardzące zasiedziałymi rozwiązaniami pokolenie programistów dla których słowo „legacy” brzmi jak przekleństwo.
Na wyższych uczelniach technicznych kształcących sól naszej ziemi czyli informatyków twórcy programów nauczania doszli do wniosku, że algebra liniowa, analiza matematyczna i rachunek prawdopodobieństwa są daleko ważniejszymi umiejętnościami przyszłego programisty niż bazy danych i język SQL.
Vendorzy regularnie wypuszczają kolejne, coraz bardziej nasycone funkcjonalnością, wersje swoich motorów baz danych z których każda wyposażona jest w coraz doskonalszy i coraz bardziej niepotrzebujący człowieka optymalizator kosztowy.
Tak zwany biznes znajduje coraz to nowe powody dla których warto zwiększyć ilość danych magazynowanych w bazach danych. Przyrost danych jest wprost proporcjonalny do niechęci do ich usuwania, archiwizowania czy choćby kompresowania.
A znający powierzchownie bazy danych i język SQL programiści wprawdzie słyszeli o indeksach, ale o partycjonowaniu już niekoniecznie.
Dzięki tym ludziom strojenie SQL nie ma końca.
Jak zacząć strojenie SQL?
Proponuję zacząć od wykształcenia w sobie umiejętności zwanej „systematyczne podejście”. Oczywiście nie mam na myśli strojenia zapytań w stylu:
SELECT * FROM tabela WHERE sysdate BETWEEN początek AND koniec;
Mam na myśli zapytania łączące dane z wielu tabel i widoków.
Pierwszym poziomem umiejętności „systematyczne podejście” jest zrozumienie najważniejszych zasad którymi kieruje się optymalizator kosztowy podczas opracowywania planu wykonania Twojego SQL. W dużym skrócie plan wykonania to sposób w jaki motor bazy danych wykona to co ma nakazane w komendzie SQL.
Łączenie tabel
Trzeba pamiętać, że łączone są jedynie dane z dwóch zbiorów na raz.
Wynik takiego złączenia jest pośrednim zbiorem danych do którego następnie dołączane są dane z kolejnej tabeli i/lub widoku. I tak dalej aż do połączenia danych z wszystkich wskazanych klauzulą FROM zbiorów danych.
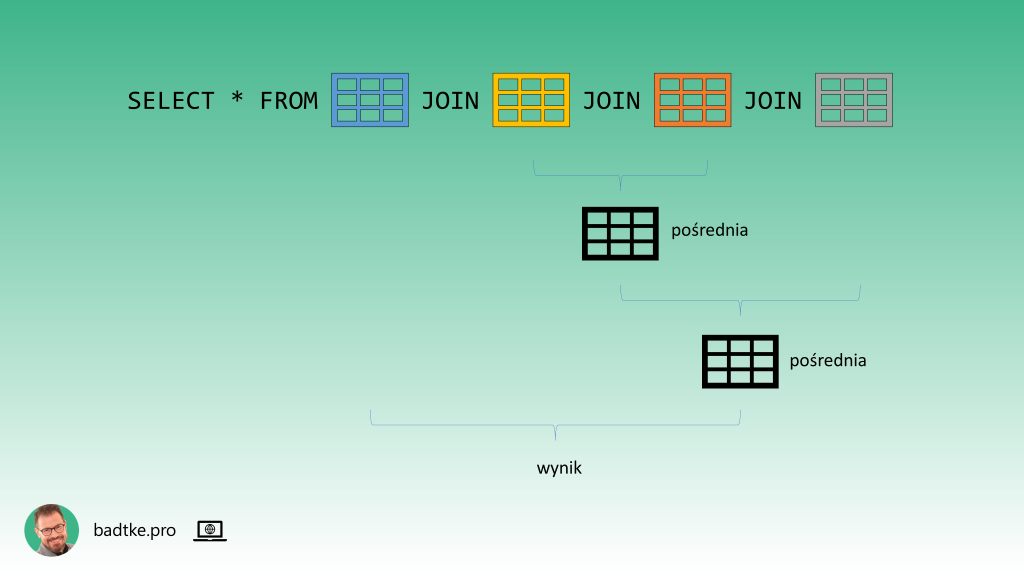
Kolejność łączenia zależy jedynie od optymalizatora. Wpływ na jego decyzje mają statystyki. Czyli informacje o rozkładzie danych w poszczególnych tabelach. Na przykład ile jest w nich wierszy oraz ile jest unikalnych wartości w kolumnach.

Sama konstrukcja komendy SQL także ma znaczenie. Z czego klauzula WHERE jest najważniejsza. Jej zadaniem jest wskazanie wierszy na których komenda SQL ma zostać wykonana. Dlatego dobierając warunki w klauzuli WHERE warto zadbać aby każdy ograniczał ilość wierszy.
Im mniejszej ilości wierszy dotyczy komenda SQL tym szybciej się wykona.
Driving table
Pierwszym krokiem do opracowania planu wykonania jest odkrycie tabeli zwanej z angielska driving table.
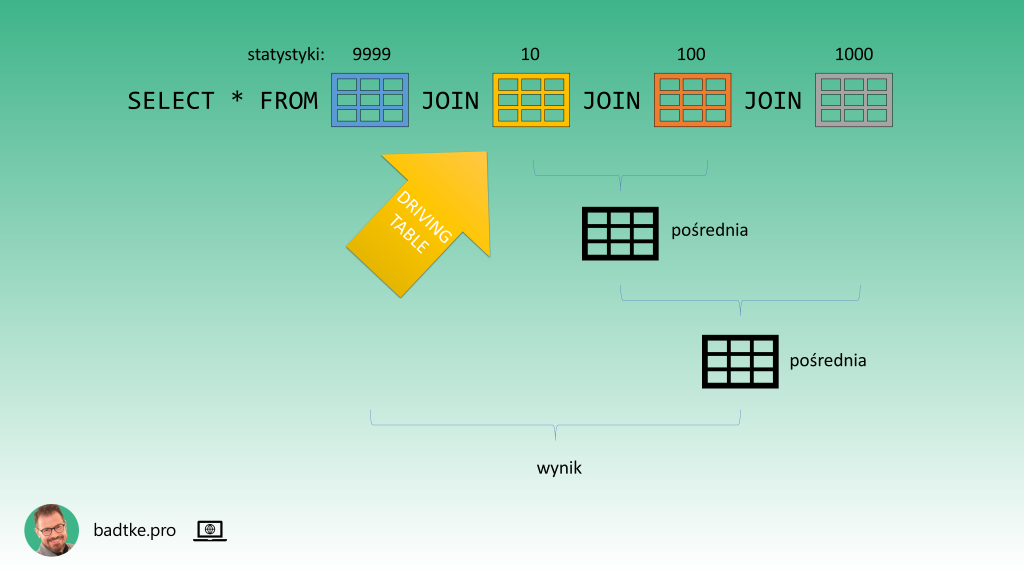
Dane z tej tabeli zostaną wybrane jako pierwsze. Do nich zostaną dołączone dane z kolejnej tabeli. Im mniej danych zostanie wybranych z driving table tym mniej zostanie wybranych z kolejnych dołączanych tabel. Najlepiej gdy dane łączone są w kolejności od liczących najmniej wierszy.
Niestety nie zawsze optymalizator wybierze właśnie ten wariant.
Czasem nieaktualne statystyki, nieoptymalna komenda SQL lub nieoptymalny schemat bazy danych wyprowadzą go na manowce.
Jak można spowodować aby podążał pożądaną przez Ciebie drogą?
Najpierw trzeba ją odkryć. Wskażą Ci ją dane.
Oglądanie danych
Systematyczne podejście polega na policzeniu tego co dla optymalizatora jest ważne. Czyli używając funkcji count liczysz ile jest rekordów w każdej tabeli oraz widoku wykorzystywanym przez kwerendę.
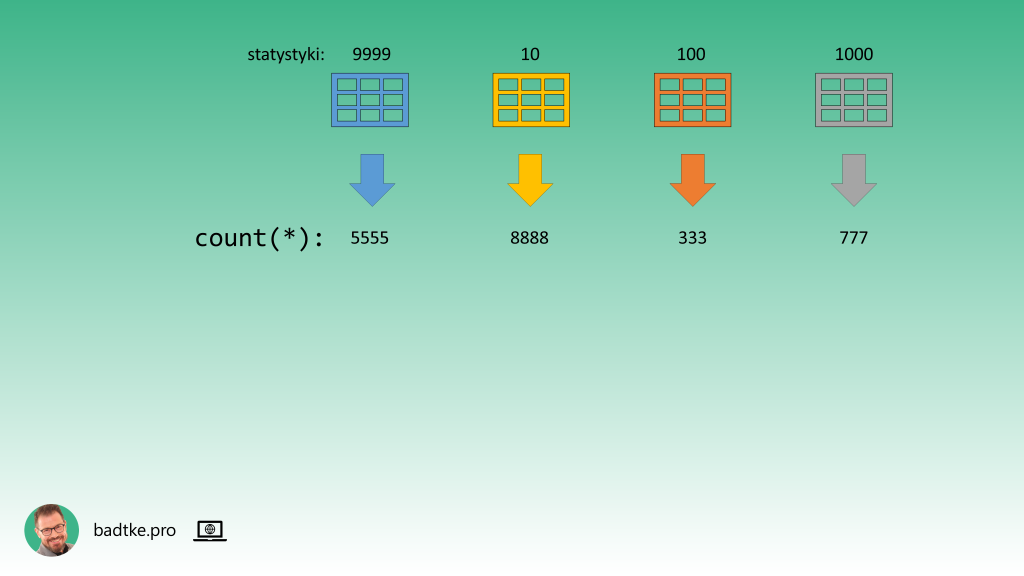
Następnie konstruujesz zapytania filtrujące.
Czyli z klauzuli WHERE wybierasz warunki dotyczące danej tabeli i liczysz, przy pomocy funkcji count, ile wierszy zostanie wybranych gdy warunki zostaną uwzględnione. W ten sposób otrzymujesz dwie liczby które pomogą wskazać driving table.
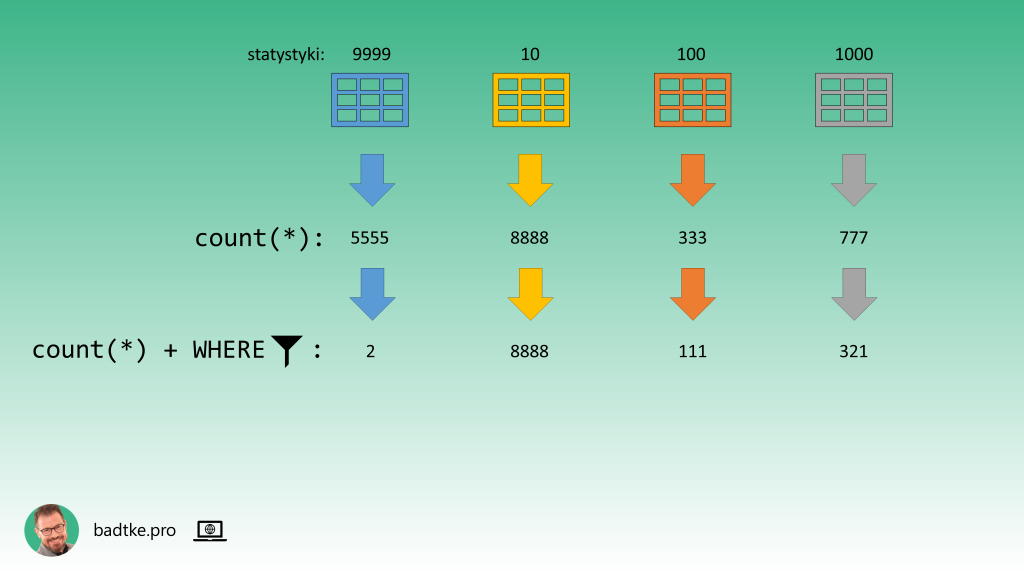
Liczby możesz wykorzystać na dwa sposoby. Pierwszy to posortowanie wyników według ilości odfiltrowanych wierszy. Ta tabela, z której zapytanie wybiera najmniej wierszy powinna być driving table.
Drugi sposób to wybranie na driving table tej tabeli, której najmniejszy procent wierszy zostaje wybrany. Czyli tej dla której warunki WHERE najlepiej filtrują dane.
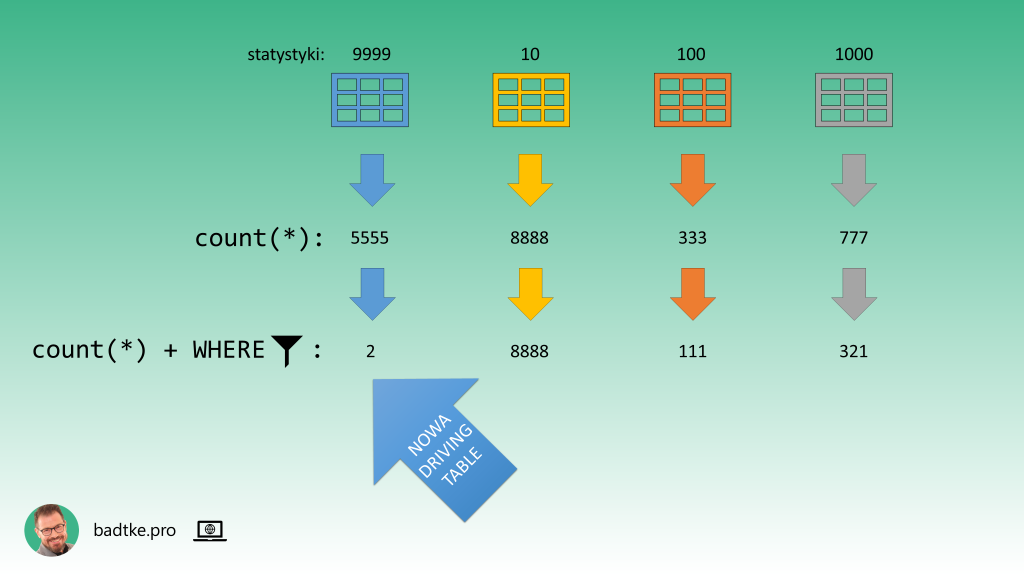
W ten sposób osiągasz poziom drugi umiejętności „systematyczne podejście”.
Zakończenie
Kolejne materiały dotyczące strojenia SQL już wkrótce.
Jeśli nie chcesz ich przegapić to wiesz co trzeba zrobić.
Staram się aby materiały były jak najbardziej ogólne czyli możliwe do wykorzystania niezależnie od motoru bazy danych. Jeśli materiał będzie dotyczyć konkretnego motoru zaznaczę to.
Do produkcji wykorzystuję książkę „Oracle SQL Performance Tuning and Optimization”. Autor: Kevin Meade. Została wydana przez Amazon.
Jeśli wymienione funkcjonalności to dla Ciebie puste dźwięki to koniecznie napisz w komentarzu. Przygotuję o nich osobne materiały.
Prowadzę szkolenia i kursy z podstaw SQL. Sprawdź ofertę moich kursów SQL.



