
Jeden język by bazami danych zarządzać, jeden by danymi manipulować, jeden by wszystkie tabele stworzyć i w zapytaniu powiązać.
Język SQL to język zapytań, a nie programowania. Jest znacznie trudniejszy do nauki niż popularna Java czy modny Python. Są po temu trzy powody. Pierwszy: musisz wiedzieć czego chcesz. Czyli jaki rezultat chcesz uzyskać i być w stanie opisać swoje żądanie w języku SQL. Drugi: musisz zaakceptować, że to motor bazy danych decyduje jak ten rezultat osiągnie. Czyli Twoje żądanie musi uwzględniać ścieżki dostępu do danych przewidziane w strukturze bazy danych. Trzeci: SQL operuje na zbiorach danych. Czyli określasz interesujący Cię zbiór danych oraz instruujesz motor bazy danych co ma z tym zbiorem zrobić. Podejmiesz wyzwanie?
Co to znaczy język zapytań?
Określeniem lepiej oddającym charakter języka SQL jest kwerenda. Czyli SQL jest językiem w którym nakazujesz motorowi bazy danych wyszukać w bazie danych interesujące Cię dane i wykonać na nich żądaną operację. Tą operacją może być wstawienie (INSERT), wybranie (SELECT), modyfikacja (UPDATE) czy usunięcie (DELETE) danych.
Trzeba podkreślić, że u podstaw jezyka SQL leżała prostota jego użycia. Projektowany był do realizacji stosunkowo nieskomplikowanych zapytań operujących na paru tabelach. W modelu relacyjnym dane poddawane są procesowi normalizacji. Czyli rozbijane na wiele tabel aby zlikwidować nadmiarowość danych i jak najtaniej składować je w bazie danych. Z drugiej strony podlegają procesowi denormalizacji przed zwróceniem ich do klienta. Proces denormalizacji w SQL nazywa się złączeniem. Po angielsku join. W procesie tym łączone są dane z kilku tabel. Im więcej tabel jest łączonych tym bardziej skomplikowana kwerenda.
Warto mieć na uwadze, że dobrą praktyką języków programowania jest pisanie stosunkowo krótkich funkcji czy procedur o precyzyjnie opisanych zadaniach. Jeśli kod funkcji się rozrasta jest coraz mniej zrozumiały dla człowieka. W związku z tym człowiek coraz bardziej narażony jest na popełnienie błędu owocującego bugiem.
Nie inaczej jest w SQL. Jeśli kwerenda mieści się w setkach linii i łączy dane z wielu tabel to coraz trudniej ją analizować. Nie tylko człowiekowi, ale także i optymalizatorowi. Czyli fragmentowi motoru decydującemu o wydajności wykonania kwerendy. Trzeba pamiętać, że optymalizotor ma skończony i bardzo krótki czas na opracowanie planu wykonania kwerendy. Gdy czas się skończy wybrany zostaje najlepszy znaleziony plan, a nie najlepszy możliwy.
Jeśli nie jesteś w stanie pisać prostych kwerend SQL realizujących Twoje zadanie to, oprócz oczywistej zbyt słabej znajomości SQL, może także znaczyć, że struktura bazy danych została nieoptymalnie zaprojektowana.
Nomenklatura
W materiale o kluczowych modelach baz danych opisałem model relacyjny. Posługiwałem się takimi terminami jak relacja, atrybut czy krotka. Wszystkimi tymi elementami posługujesz się także w języku SQL tylko nazywają się inaczej.
Trzeba pamiętać, że język SQL powstał 50 lat temu dla ludzi nietechnicznych. Przyzwyczajeni byli do operowania pojęciami rodem z papierowych kwestionariuszy. Dlatego znana z modelu relacyjnego relacja w języku SQL zamienia się w tabelę, atrybut w kolumnę, a krotka w wiersz. Z angielska row. Po polsku pieszczotliwie rowek. Możesz także spotkać określenia rekord lub rządek.
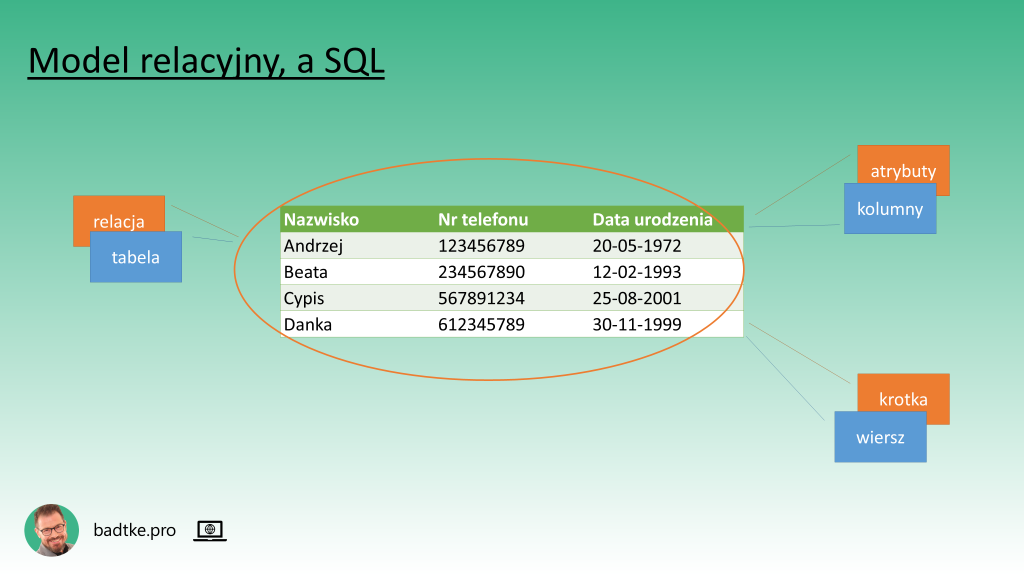
Model relacyjny tworzony był przez jajogłowych naukowców pracujących w IBM. Dedykowany był nerdom. Bazował na matematycznej teorii zbiorów. Natomiast SQL powstawał z myślą o całej rzeszy pracowników biurowych potrzebujących wygodnego dostępu do danych. Inne grupy docelowe. Swoją drogą ciekawe jak się czują współcześni programiści mając świadomość, że nie ogarniają języka stworzonego dla pani Danki z księgowości.
Główne zadania SQL
Przed językiem SQL postawiono dwa zadania. Pierwsze to definiowanie struktur bazy danych. Czyli tworzenie bazy danych, obiektów, które ma zawierać oraz określanie uprawnień do danych. Drugie zadanie to manipulacja danymi. Czyli ich wstawianie, wybieranie, modyfikowanie i usuwanie. Pomyślany jako język przyjazny dla anglosaskiego użytkownika słowa kluczowe czerpie z języka angielskiego.
Możesz spotkać się z akronimami grupującymi komendy języka SQL. Na przykład część odpowiedzialna za definiowanie struktury bazy danych to DDL. Po angielsku Data Definition Language. Zwróć uwagę na angielskie rozwinięcie akronimu. Tłumaczone dosłownie oznacza definiowanie danych. I to jest sens relacyjnej bazy danych. Swoją sztywną strukturą definiuje kształt danych w bazie danych. Tabelę należy postrzegać jako definicję danych, a nie kontener na dane. Programiści obiektowi mogą wyobrażać sobie tabelę jako klasę, a wiersze z danymi jako obiekty tej klasy.
Część odpowiedzialna za manipulowanie danymi to DML. Czyli Data Manipulation Language. Są jeszcze dwie małe części. DCL czyli Data Control Language odpowiedzialna za manipulację uprawnieniami. Oraz TCL czyli Transaction Control Language której zadaniem jest kontrola transakcji. Czyli jej rozpoczęcie lub zakończenie.
Według mnie komendy języka SQL odpowiedzialne za manipulację danymi można podzielić na dwie części. Te które używają klauzuli WHERE i te które jej nie używają. Klauzula WHERE jest kluczowa w przypadku posługiwania się jezykiem SQL. To na niej skupię się w swoim kursie SQL dla początkujących.
Sposób pracy
W klasycznych językach programowania najpierw budujesz zbiór danych. Zasysasz go element po elemencie i wstawiasz do struktury danych zbudowanej w swoim programie. Na przykład tablicy lub listy. Następnie budujesz pętelkę w której wykonujesz jakąś akcję iterując element po elemencie przez tę strukturę. Najwięcej czasu poświęcasz na optymalizowanie tej pętelki. O dostęp do danych nie trzeba się martwić bo tablica z zasady jest poindeksowana, a elementy listy powiązane.
W SQL jest nieco inaczej. Najwięcej czasu poświęcasz na precyzyjne określenie zbioru danych. To jest sławna klauzula WHERE. Następnie mówisz motorowi bazy danych co ma zrobić z danymi w zbiorze. Czy ma je zmodyfikować czy wybrać z bazy danych. Budowę optymalnej pętelki do iteracji po elementach zbioru bierze na siebie motor bazy danych. Także motor bazy danych decyduje jak żądane dane w bazie danych wyszuka.
Trzeba pamiętać, że dane w bazie danych nie są w żaden sposób posortowane. Nowe dane rzucane są przez motor na bezładną stertę. Czyli zapisywane w plikach bazy danych tam gdzie jest wolne miejsce. Jak możesz się domyślać przeszukanie takiej bezładnej sterty kosztuje dużo zasobów. Dlatego twórcy baz danych zaimplementowali w motorach indeksy. Są to struktury zawierające posortowany wycinek danych. Są zoptymalizowane do szybkiego przeszukiwania, ale tylko po tym wycinku danych. Czas przeszukiwania indeksu jedynie w minimalnym stopniu zależy od ilości poindeksowanych danych. Czyli bardzo dobrze się skaluje. Indeks możesz wyobrazić sobie jako skorowidz w książce.

Gdy motor bazy danych nie może znaleźć optymalnego indeksu wtedy zaczyna przeglądać dane wiersz po wierszu. Robi to bardzo szybko. Niemniej gdy ma do przejrzenia miliony albo miliardy wierszy to czas realizacji takiego zadania jest nieakceptowalnie długi. Podczas skanowania całej tabeli motor zużywa duże ilości CPU i obciąża system dyskowy. Zazwyczaj wolisz aby w dostępie do danych używał indeksu.
Kluczem do sukcesu w używaniu języka SQL jest umiejętne wykorzystanie indeksów w dostępie do danych. Aby umiejętnie je wykorzystać trzeba umieć je odkryć i znać ich mechanikę. Ale to temat na mój powstający kurs SQL dla początkujących.
Standard
Język SQL jest ustandaryzowany przez instytucje ANSI i ISO. Ostatnia edycja miała miejsce w 2023. Zawierała funkcjonalności wspierające manipulowanie danymi w formacie JSON. Niemniej trzeba pamiętać, że żaden producent motoru baz danych nie implementuje standardu w 100%. Każdy dodaje także swoje specyficzne smaczki ułatwiające korzystanie z jego motoru.
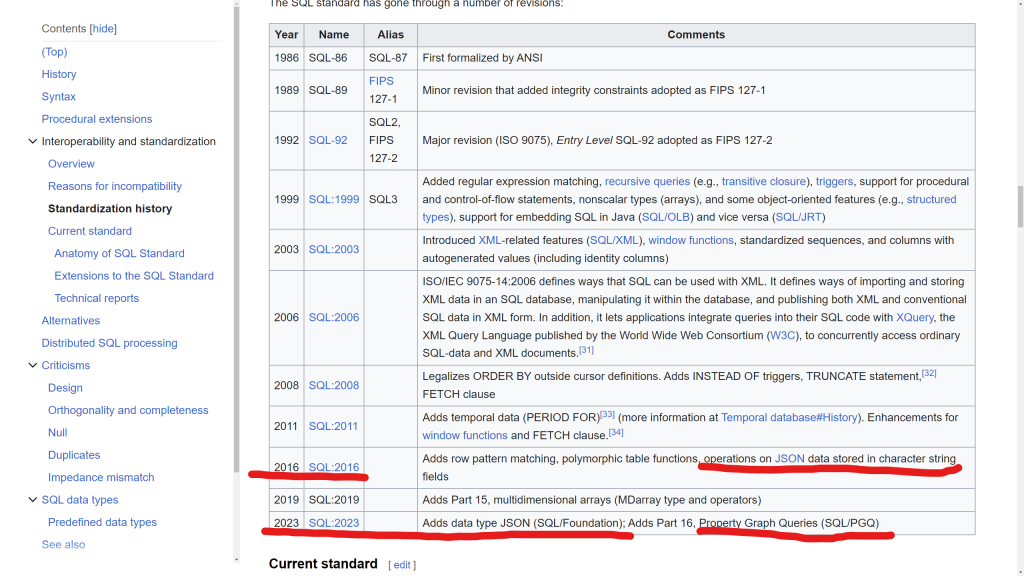
Jakby nie było trzymanie się standardu, czyli unikanie używania hermetycznych dla vendora motoru dodatków, gwarantuje bardziej smukłą przenaszalność na inny motor. Innymi słowy minimalizuje zależność od konkretnego motoru bazy danych. Jest to bardzo optymistyczna wizja. Trzeba mieć na uwadze, że motory baz danych różnią się nie tylko stopniem implementacji standardu języka SQL. Duże znaczenie mają różnice w mechanice obsługi współbieżności. Jest to obszerny temat, który będę kontynuował w następnych materiałach.
Nie samym SQL aplikacja żyje
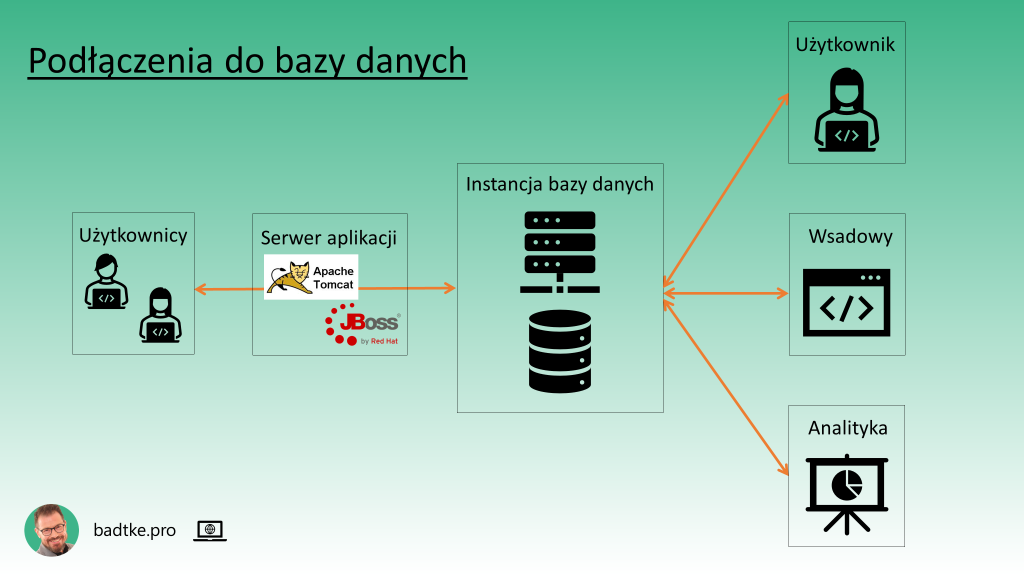
Motor bazy danych jest najbliższym danych oprogramowaniem. Cokolwiek chcesz z danymi zrobić motor bazy danych zrobi to najbardziej wydajnie. Tylko trzeba umieć używać zaimplementowanych w nim narzędzi. Oprócz języka SQL takim narzędziem jest język proceduralny. Każdy motor baz danych ma swój unikalny. Język taki pozwala na pisanie bardziej skomplikowanych niż kwerenda programów i składowanie ich w bazie danych. Mogą przybrać formę procedur lub funkcji. Mogą być grupowane w pakiety. Zazwyczaj uruchamiane poprzez intencjonalne wywołanie. Gdy przyjmą postać wyzwalacza, po angielsku trigger, mogą być uruchamiane automatycznie na skutek zdarzenia w bazie danych. Na przykład modyfikacji danych czy logowania użytkownika do bazy danych.
Przy pomocy języka proceduralnego w bazie danych zwykło się zaszywać tak zwaną logikę biznesową. Dzięki umieszczeniu kodu tak blisko danych jak to tylko możliwe oszczędzano czas potrzebny na transfer sieciowy. Oszczędzano także czas potrzebny na kodowanie w aplikacji algorytmów, które zostały zaimplementowane w motorze bazy danych.
Część motorów baz danych umożliwia pisanie procedur i funkcji w językach programowania jak Java oraz składowanie ich w bazie danych. Wg mnie jest to ostateczność gdy SQL i natywny język proceduralny okażą się naprawdę niewystarczające. Używanie Javy do przetwarzania danych tylko dlatego, że programista w niewystarczającym stopniu zna SQL jest niepotrzebną komplikacją projektu.
Trzeba pamiętać, że sposoby produkowania aplikacji zmieniają się co parę lat. Współcześnie mało kto pamięta o monolitycznych aplikacjach pisanych w C i C++. Obecnie modny jest wysokopoziomowy Python i mikroserwisy. Natomiast najważniejsze dane w dalszym ciągu utrwalane są w relacyjnych bazach danych. Relacyjne motory ciągle rozbudowywane są o nowe, zgodne z potrzebami rynku, funkcjonalności. Dzięki temu logika biznesowa trzymana w bazie danych nie musi być co parę lat przepisywana aby pozostawać w zgodzie z aktualnymi trendami.
Mało tego, powstają nowe motory relacyjne optymalizowane pod konkretne środowisko. Na przykład Snowflake optymalizowany pod środowisko chmurowe.
Najnowszym trendem jest uczenie maszynowe. Wiodący producenci motorów baz danych dokładają funkcjonalności pozwalające na tworzenie modeli w bazie danych.
W dobie silnego wzmożenia cyber ataków na dane ważnym zastosowaniem funkcjonalności bazy danych i zaszytego w niej języka proceduralnego jest dbanie o bezpieczeństwo i jakość danych. Trzeba pamiętać, że nie tylko aplikacja łączy się do bazy danych i nie tylko aplikacja może danymi manipulować. Część użytkowników łączy się bezpośrednio. Baza danych może być zasilana danymi z innych systemów lub służyć jako źródło danych dla systemów analitycznych.
Podsumowanie
Przez 50 lat nie wymyślono lepszego API do danych niż język SQL. Konkurencji nawet nie widać na horyzoncie. Nawet producenci nierelacyjnych motorów baz danych, w których zaimplemenowali własny język zapytań odpowiadają na potrzeby rynkowe i implementują SQL.
Język ciągle dostosowywany jest do zapotrzebowania rynku. W ostatniej edycji rozszerzono możliwości manipulacji danymi w formacie JSON.
SQL używany razem z motorem multimodel powiąże,w jednym zapytaniu, dane z wielu modeli danych. Wykorzystując mechanizmy ACID zadba o spójność danych niezależnie od ich modelu.
Z pewnością nie możesz doczekać się kiedy poznasz język SQL bliżej. Mam dla Ciebie dobrą wiadomość. Prowadze kursy z podstaw SQL. Darmowa wersja dostępna jest na moim blogu i kanałach w mediach społecznościowych.
To szósta część cyklu o ekosystemie bazy danych.
Poprzednia: 2 kluczowe modele bazy danych.
Ta część kończy cykl o ekosystemie bazy danych. Jeśli widzisz potrzebę kontynuowania cyklu daj znać w komentarzu jakie tematy byłyby wartościowe dla Ciebie.



