
Wstęp
Podczas projektowania bazy danych, w efekcie normalizacji, otrzymujesz czasem tabelę w skład której wchodzi wiele kluczy obcych o nie intuicyjnych wartościach. Aby dane te zamieniły się w informacje trzeba połączyć tabele główne ze słownikowymi. Innym razem, ze względów bezpieczeństwa lub funkcjonalnych, część danych tabeli głównej wydzielasz do tabeli dodatkowej. Niemniej odpowiedni użytkownicy powinni mieć dostęp do obu połączonych fragmentów. Ze względów wydajnościowych i bezpieczeństwa danych warto aby dostęp do danych przebiegał zawsze w ten sam i ściśle kontrolowany sposób. Do tego i wielu więcej możesz wykorzystać widoki.
Co to jest widok?
Jak wiesz z innych moich materiałów w SQL wszystko jest tabelą. W szczególności wynik komendy SELECT. Widok jest komendą SELECT zapisaną w bazie danych. Podkreślam: komendą, a nie wynikiem komendy. Gdy się do widoku odwołasz zapisana komenda SELECT zostanie wykonana i na bieżąco wygeneruje wynik, który zwróci w postaci tabeli. Można, więc użyć skrótu myślowego i powiedzieć, że widok jest wirtualną tabelą. Czyli obiektem, który nie przechowuje żadnych danych, a jedynie w momencie użycia udostępnia te wymienione w swojej definicji. Warto wiedzieć, że inną nazwą widoku jest perspektywa. Tabele z których widok czerpie dane nazywane są tabelami bazowymi. Mogą to być także inne widoki. Jako administrator baz danych powiem, że budowa widoków czerpiących dane z innych widoków utrudnia rozwiązywanie problemów wydajnościowych.
Co można widokiem osiągnąć?
Pierwsze zastosowanie widoków to ukrycie skomplikowanej logiki zapytania. Na przykład łączenia wielu tabel czy złożonych warunków. Takie zapytania warto mieć zapisane w jednym miejscu gdzie mogą być łatwo modyfikowane i udostępniane wielu użytkownikom.
Drugie to ograniczenie dostępu do danych w celu poprawy bezpieczeństwa. Czyli zamiast szerokiego dostępu do zawierającej dane wrażliwe tabeli bazowej nadajesz dostęp do widoku zbudowanego jedynie na wybranych kolumnach.
Trzecie to zdefiniowanie jednolitej struktury danych w celu ustandaryzowania wyniku. Na przykład raportów czy eksportu danych. Dzięki temu różne systemy lub użytkownicy dostają identyczny i aktualny wynik.
Czwarte to możliwość dostosowania do konkretnych potrzeb określonych użytkowników. Widoki pozwalają spojrzeć na dane Twojej bazy danych z różnych perspektyw w zależności od potrzeb informacyjnych konkretnych użytkowników.
Piąte to wymuszenie spójności danych przy pomocy widoków walidujących o których w dalszej części materiału. Warto pamiętać, że klauzulą WHERE możesz filtrować wiersze zwracane przez widok używając jedynie kolumn występujących w definicji widoku.
Widok danych
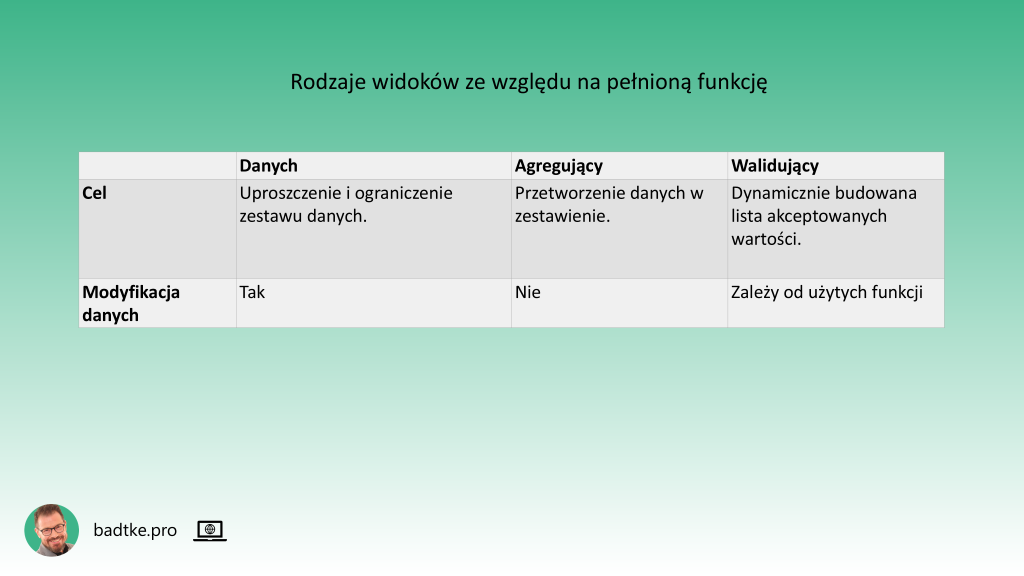
Na etapie projektowania logicznej struktury bazy danych można, ze względu na pełnioną funkcję, wyróżnić trzy typy widoków. Pierwszy z nich to najprostszy widok danych.
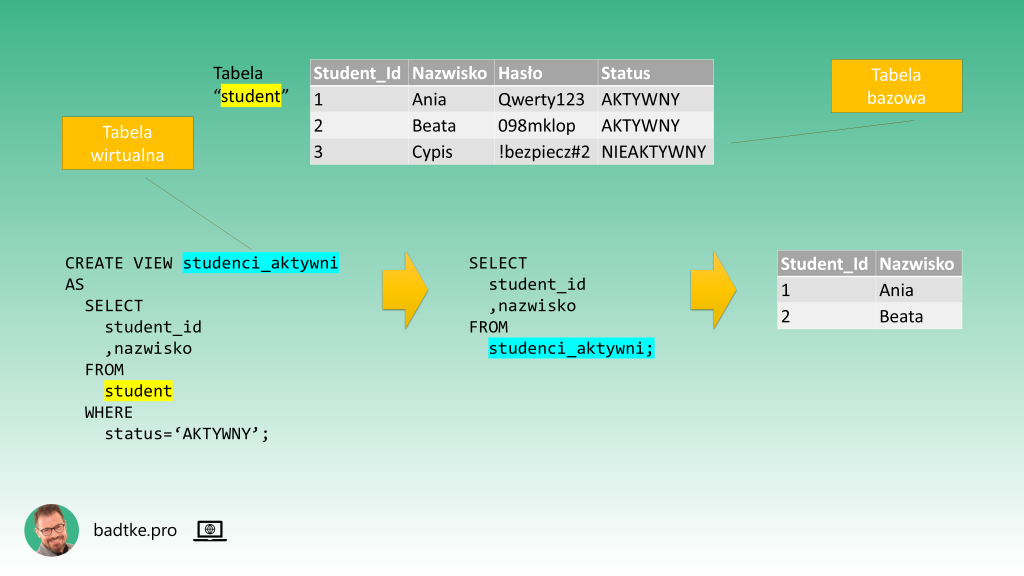
Jego celem jest udostępnienie użytkownikom określonego zestawu danych w uproszczonej, poprawiającej czytelność lub ograniczającej widoczność tylko do wybranych kolumn lub wierszy formie. Na przykład widok pokazujący nowe zamówienia i drugi pokazujący zamówienia gotowe do wysyłki. Oba korzystające z tej samej tabeli bazowej, ale udostępniające jedynie dane potrzebne do pracy danej grupie użytkowników. Poprawia to organizację pracy pod kątem konkretnych zadań. Szczególnym przypadkiem ograniczenia dostępu do niektórych kolumn czy wierszy jest perspektywa poprawy bezpieczeństwa danych. Jeśli w skład tabeli wchodzą kolumny z danymi wrażliwymi lub niejawnymi to możesz zbudować widok zwracający jedynie dane z kolumn publicznych. Zmniejsza to ryzyko nieautoryzowanego dostępu. Warto pamiętać, że w zależności od konkretnego motoru bazy danych, najprostsze widoki mogą umożliwiać modyfikację danych w tabeli bazowej.
Widok agregujący
Głównym celem widoku agregującego jest udostępnienie użytkownikom informacji powstałych w wyniku przetwarzania danych. Na przykład sum, średnich, zliczeń. Może wykorzystywać do tego najprostsze funkcje agregujące jak również zaawansowane funkcje analityczne. Oprócz tego może zawierać kolumny wynikające ze sklejenia innych, wyliczane wyrażenia czy wyniki działania funkcji. Widok zawsze generuje wynik w oparciu o aktualne dane z tabel bazowych. Jakiekolwiek, więc podsumowanie pokazuje stan na dany punkt w czasie. Z uwagi na to, że kolumny widoku są wyliczane modyfikacja poprzez widok agregujący danych w tabeli bazowej jest niemożliwa. Widok agregujący jest szczególnie przydatny w raportowaniu i analizie biznesowej. Dzięki zapisowi zapytania w bazie danych ujednolica sposób liczenia wskaźników. Na przykład sprzedaży miesięcznej.
Widok walidujący
Widok walidujący służy podobnym celom jak tabela walidująca omówiona w materiale 4 funkcjonalne typy tabel. Różnicą jest, że tabela ma listę wartości zapisaną i rzadko modyfikowaną podczas gdy lista wartości zwracana przez widok jest każdorazowo budowana na podstawie danych tabel bazowych. Dodatkowo widok walidujący może czerpać dane z wielu tabel bazowych. Błędem projektowym jest przechowywanie w kolumnie tabeli wartości wyliczanych. Te zasady nie dotyczą widoku. Możesz stworzyć widok, który zwraca listę wartości wyliczanych na bieżąco w momencie wykonania na nim komendy SELECT. Na przykład poprzez sklejenie kolumn, użycie funkcji czy agregację. Dzięki temu możesz walidować wartości kolumn tabeli głównej w oparciu o aktualne dane.
Widok partycjonowany
Na etapie implementacji projektu bazy danych w konkretnym motorze można wyróżnić dwa typy widoków. Pierwszy to partycjonowany. Świetna opcja dla osób, które nie chcą płacić dostawcy motoru bazy danych za funkcjonalność partycjonowania. Na przykład firmie Oracle. Widok partycjonowany tworzy logiczną całość z wielu komend SELECT połączonych poleceniem UNION ALL. Najczęściej każdy SELECT jest do innej tabeli, a tabele mają zbliżoną strukturę.

Przykładem użycia może być archiwizacja danych. Za każdym razem dane za nowy okres pojawiają się w nowo tworzonej tabeli. Na bieżącej i archiwalnych zbudowany jest widok. Innym przykładem jest unifikacja dostępu do tabel o podobnej zawartości lecz odmiennej strukturze. Czyli zamiast kosztownie dostosowywać strukturę istniejących tabel można stworzyć unifikujący widok. Na przykład po połączeniu różnych systemów pełniących podobną funkcję. Gdy optymalizator znajdzie na tabelach indeksy odpowiadające klauzuli WHERE jest szansa, że ograniczy przeszukanie do ograniczonej liczby tabel. Zachowa się tak optymalizator Oracle.
Widok zmaterializowany
Wszystkie wcześniej wspomniane widoki można wykorzystać do stworzenia widoku zmaterializowanego. Czyli widoku, który wykonuje zapytanie SELECT zapisane w definicji, a wynik tego zapytania zachowuje w bazie danych. Jest to drugi typ widoku, który możesz wybrać na etapie implementacji projektu bazy danych.
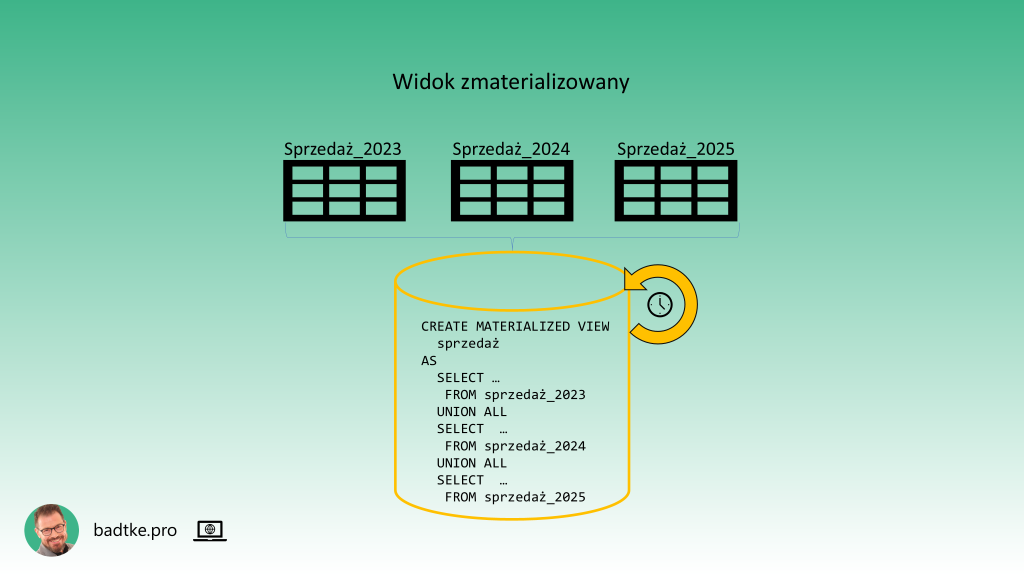
Motory dostarczające funkcjonalności widoku zmaterializowanego zazwyczaj pozwalają na automatyczne odświeżanie danych w takim widoku. Korzyściami są:
- poprawa wydajności zapytań
- stabilizacja wyniku na punkt w czasie
Szczególnie jeśli widok wykonuje wiele lub skomplikowane agregacje i złączenia tabel. Motor nie musi już tego robić dla każdego odwołania do widoku bo ich wynik jest zapisany w bazie danych. Minusami są:
- większa konsumpcja przestrzeni dyskowej
- aktualność danych na punkt odległy w przeszłości o czas pomiędzy odświeżaniami
Podsumowanie
Dziękuję za przeczytanie niniejszego materiału. Wiesz z niego, że
- widoki odgrywają bardzo istotną rolę w warstwach abstrakcji relacyjnej bazy danych. Pomagają oddzielić logikę zapytań od fizycznej struktury danych, co przekłada się na większą elastyczność, bezpieczeństwo i klarowność systemu
- pozwalają tworzyć logiczne reprezentacje danych, które ukrywają złożoność struktury fizycznej. Na przykład złożone JOIN-y czy filtrowanie
- ograniczają widoczność danych, pokazując tylko wybrane kolumny lub wiersze
- nadają sens i kontekst dzięki agregacji, grupowaniu lub nadawaniu aliasów kolumnom, dzięki czemu dane są łatwiejsze do zrozumienia
- działają jako warstwa buforowa między aplikacją a strukturą bazy. Można zmieniać tabele bazowe, na przykład refaktoryzować kolumny, a widok utrzyma spójność interfejsu
- poprawiają wydajność kosztem aktualności danych i przestrzeni dyskowej w przypadku widoków zmaterializowanych
Niech przejrzystość widoków zawsze rozjaśnia Twoją bazę danych! A jeśli chcesz, by Twoje widoki elegancko i wydajnie zamieniały dane w informacje – koniecznie śledź mój blog!



